
Le Model Context Protocol est un protocole, proposé par Anthropic (Claude), qui permet d’intégrer facilement des sources et outils externes à des applications utilisant des LLM. Le LLM, au lieu d’appeler des outils, appellera le serveur MCP pour enrichir son contexte. Cela permet de construire plus facilement des agents, en fournissant rapidement une intégration avec différents services que les LLM peuvent intégrer.
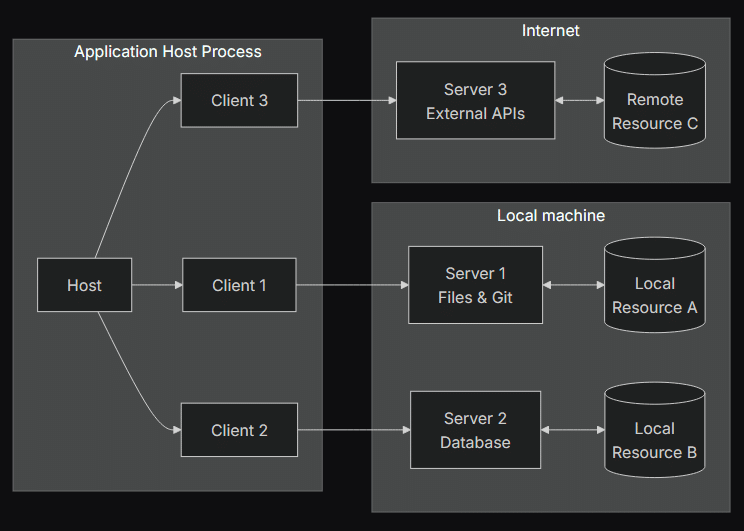
Comment fonctionne ce protocole ? Il y a 3 composantes principales pour le protocole MCP :
- L’hôte qui centralise et coordonne les différentes actions du système.
- Les clients qui communiquent chacun avec un seul serveur.
- Les serveurs qui fournissent les contextes supplémentaires et les nouvelles possibilités.
Le protocole MCP se base sur JSON/RPC, une norme du JSON qui permet d’appeler une fonction sur le destinataire en envoyant une méthode et ses paramètres.
Exemple de requête :
{
"jsonrpc": "2.0",
"id": 1,
"method": "roots/list"
}Les communications se font entre les serveurs et les clients, et chaque serveur est considéré comme un outil qui fournit des possibilités qu’il déclare.
L’objectif du protocole MCP est de faciliter l’intégration d’outils dans le LLM. Pour cela, la création de serveurs est facilitée et ils peuvent facilement évoluer pour proposer plus de fonctionnalités.
On veut aussi que les possibilités qu’offrent les différents serveurs qu’on connecte à notre hôte puissent facilement interagir et se compléter sans que les serveurs aient connaissance de tout le contexte, autres serveurs inclus. Cette isolation est importante pour garantir l’imperméabilité des données entre les serveurs.
On va voir comment les composants du MCP interagissent ensemble pour cela et quel est leur rôle dans le protocole.
Le serveur
Le rôle du serveur est de fournir un certain nombre de capacités pour enrichir le LLM de l’hôte. Il fournit 3 types de capacités :
- Les prompts
- Les ressources
- Les outils
Les prompts fournis par le serveur ont vocation à être contrôlés par l’utilisateur pour aider à découvrir les autres capacités du serveur. C’est typiquement une commande que peut entrer l’utilisateur. Le serveur lui associe une description et, si le prompt le demande, les arguments qu’on peut passer au prompt.
Ensuite, on a les ressources, ce sont généralement des fichiers que met le serveur à disposition pour enrichir le contexte de la demande de l’utilisateur. Comme indiqué, ça peut être un fichier, mais aussi une ressource sur le net, dont on a l’URL, ou encore un repository Git. Quand un serveur déclare une ressource, on lui associe aussi une description.
Enfin, les outils, ce sont des actions que peuvent effectuer le serveur. Elles sont destinées à être utilisées par le LLM lorsqu’il a besoin de récupérer des informations, ou parce qu’on lui demande de faire une action. C’est en tout point similaire aux outils qu’on utilise avec les LLM, comme expliqué dans cet article sur le pattern ReAct. Le serveur fournit aussi une description de cet outil.
Ces capacités, le serveur les déclare à l’initialisation du protocole au client.
Le serveur peut aussi avoir besoin de ressources du client, auquel cas il les demande à celui-ci. C’est ensuite le client qui décide de lui envoyer ce qu’il faut parmi les ressources qui lui sont accessibles.
Le client
Le rôle du client, quant à lui, est de transmettre les demandes de l’hôte aux serveurs et inversement. C’est le client qui assure la communication avec le serveur et qui gère aussi ce à quoi le serveur a accès ou non. Pour ça, le client fournit 2 types de capacités au serveur :
- Les roots
- Les samplings
Les roots, c’est simplement les différentes ressources / fichiers auxquels aura accès le serveur. Ceci est généralement restreint au niveau d’un dossier ou d’un espace de travail défini.
Les samplings ne sont pas vraiment des ressources que met à disposition les clients, c’est plutôt une possibilité qu’offre le client au serveur de faire une demande au système pour avoir plus d’informations. Par exemple, le serveur peut demander au client de lui indiquer quelle est la météo de demain pour pouvoir retourner les informations qu’on lui demande. La demande peut contenir du texte, une image ou de l’audio.
Le client approuve ou non la demande, et si elle est approuvée, la demande est transmise à l’hôte.
Le serveur, lors de sa demande de sampling, peut aussi donner des indications sur le modèle à utiliser, soit en donnant le nom de celui-ci, soit en donnant des informations générales sur le modèle en se basant sur l’importance du coût, de la rapidité ou de l’intelligence du modèle.
Cependant, ces indications sont purement consultatives : le client choisit au final, le LLM qui sera utilisé.
{
"hints": [
{ "name": "claude-3-sonnet" }, // Prefer Sonnet-class models
{ "name": "claude" } // Fall back to any Claude model
],
"costPriority": 0.3, // Cost is less important
"speedPriority": 0.8, // Speed is very important
"intelligencePriority": 0.5 // Moderate capability needs
}Enfin, le client a aussi pour rôle de faire des demandes à l’utilisateur pour confirmer certaines actions. En ça, il a un rôle de sécurisation qui est double : d’un côté, il peut redonner la main à l’utilisateur, et on a vu avec les roots qu’il contrôle aussi les informations auxquelles a accès un serveur.
L’hôte
Nous avons, en dernier, l’hôte. Le rôle de l’hôte dans le protocole MCP est d’orchestrer les appels aux différents serveurs en fonction de ce dont à besoin l’application. C’est lui qui a la connaissance de l’entièreté du contexte de la demande d’un utilisateur et, par conséquent, c’est lui qui décide de ce qu’il faut, ou de ce qu’on peut envoyer à tel ou tel serveur MCP. Cela signifie aussi qu’il agrège le contexte qu’il reçoit des différents clients pour le redistribuer.
Il a aussi connaissance des différents modèles auxquels a accès le système complet. C’est aussi lui qui contrôle le cycle de vie des clients. Il les crée et définit ce que chacun des clients peut faire. Il s’assure aussi que la volonté de l’utilisateur est respectée, en lui demandant son consentement pour certaines actions et en appliquant les règles de sécurité.
Comment se déroule une interaction avec le protocole MCP ?
Maintenant qu’on a découvert les acteurs principaux de ce protocole, comment se déroule une interaction typique avec MCP ?
On peut le résumer avec le diagramme de séquence qui suit :
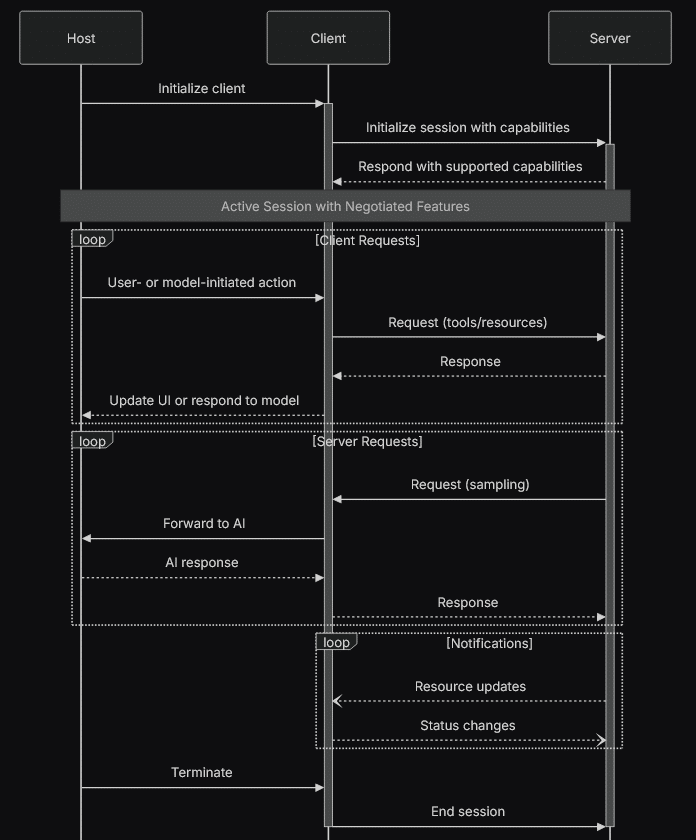
Que montre ce diagramme ? Lors de l’initialisation, l’hôte crée les clients dont il a besoin pour interagir avec les serveurs dont il a connaissance. Quand le client est créé, il va débuter une session avec le serveur. Pour ça, il lui envoie une requête avec ses roots et ses samplings lors de l’initialisation, et le serveur va lui répondre avec ses prompts, ses ressources et ses outils. Le client et le serveur savent maintenant ce que chacun peut faire.
Ensuite, il y a plusieurs types d’interactions possibles.
- L’hôte initie une action (c’est-à-dire que l’utilisateur rentre un prompt ou un modèle à besoin d’une info). Dans ce cas, le client qui peut répondre à cette demande (choisi par le LLM) va faire une requête au serveur lui demandant la ressource ou appelant l’outil nécessaire. Le serveur répond et le client transmet les infos, soit au modèle, soit à l’utilisateur.
- Le serveur fait une demande de sampling au client, car il a besoin d’une info qui lui manque. Dans ce cas, le client va transmettre la demande à l’hôte qui peut l’envoyer au LLM, en faisant ou non une demande de consentement à l’utilisateur. Il transmet alors la réponse du LLM au client, qui la fournit ensuite au serveur.
- Le serveur ou le client a été mis à jour avec des capacités supplémentaires ou en moins, alors il notifie sa contrepartie avec ces changements.
La session entre le serveur et le client se termine uniquement quand l’hôte demande au client d’y mettre fin, ou quand le serveur la coupe (ce qui devrait être plus rare).
Conclusion
Voilà un petit tour d’horizon du protocole MCP. J’ai laissé quelques détails de côté, notamment la pas-si-anecdotique partie sur l’autorisation entre client et serveur (sachez qu’il est recommandé d’implémenter les spécifications OAuth 2.1 et 2.0). Le protocole est finalement assez simple à comprendre et je pense que c’est cette simplicité qui lui a fait prendre une belle avance dans la course au standard sur la définition d’outils.
Il faut savoir que plusieurs SDK sont déjà disponibles pour implémenter et communiquer avec ce protocole, que ce soit en Python, JS, C#, Java, Swift ou encore Kotlin.
Le fait que plusieurs grands groupes, comme Microsoft avec Azure ou Hashicorp pour Terraform aient fourni des serveurs MCP pour leurs plateformes aide aussi à l’adoption.
Si vous voulez en savoir plus, je vous recommande le site officiel du protocole, qui est la source principale de cet article. Le site est bien fait, avec plein d’exemples et de schémas si vous voulez rentrer dans les détails, mais aussi avec des tutoriels, si vous préférez rentrer dans le concret plus rapidement.

