
Nos objectifs
- Comprendre ce que sont les ontologies et leur intérêt dans la représentation d’un
domain knowledgex pour les SI et les IA. - Onboarder sur la création d’une ontologie avec un cas d’usage juridique.
- Visualiser l’ontologie créée.
- Développer une intuition de ce qui peut être fait à partir de là, en termes de prochaines étapes impliquant des ontologies.
Introduction aux Ontologies : Organiser la Connaissance pour les SI (et les IA)
Imaginez que vous deviez expliquer un domaine complexe, comme les bases du droit des contrats, à un ordinateur. Vous ne listeriez pas simplement des lois au hasard. Vous définiriez les concepts clés (comme ‘Contrat’, ‘Partie Contractante’, ‘Obligation’) et les relations qui les lient (une ‘Partie Contractante’ signe un ‘Contrat’, un ‘Contrat’ crée une ‘Obligation’).
Une ontologie, c’est précisément cela : une manière formelle et structurée de représenter les connaissances d’un domaine spécifique. Elle définit explicitement :
- Les Concepts (ou Classes) : Les principaux types d’éléments existant dans ce domaine (ex: ‘Contrat’, ‘Loi’, ‘Article de Loi’, ‘Tribunal’).
- Les Propriétés (ou Attributs) : Les caractéristiques de ces concepts (ex: un ‘Contrat’ a une ‘date de signature’, une ‘Loi’ a un ‘numéro’).
- Les Relations : Comment les concepts sont connectés entre eux (ex: une ‘Partie Contractante’ est liée par un ‘Contrat’; un ‘Article de Loi’ fait partie de une ‘Loi’).
- Les Règles et Contraintes : Parfois, des axiomes ou des règles logiques (ex: un ‘Contrat’ doit avoir au moins deux ‘Parties Contractantes’).
Visualisez cela comme la création d’un dictionnaire et d’une carte relationnelle ultra-détaillés pour un sujet donné (ici, le droit), conçus pour qu’un ordinateur puisse les comprendre et les utiliser. Cela fournit un vocabulaire et un cadre partagés, garantissant que tout le monde (en chair et en os, ou en silicone pour les IA) parle de la même chose, de la même manière et sans ambiguïté.
Pourquoi utiliser des ontologies dans les systèmes automatisés ?
Même avant l’essor actuel de l’IA, les ontologies étaient précieuses car elles permettent de :
- Fournir une Structure : L’informatique a besoin de données structurées et formattées d’une certaine manière. Les ontologies transforment des connaissances du monde réel, souvent non structurées et chaotiques, en informations organisées qu’un système peut traiter.
- Permettre le Raisonnement Automatique : En définissant les relations (par exemple, si un ‘Contrat de Vente’ est un type de ‘Contrat’), un système peut déduire de nouveaux faits sans qu’on les lui ait explicitement indiqués (ex: si ce document est un ‘Contrat de Vente’, alors il est aussi un ‘Contrat’ et doit en respecter les règles générales). On peut ainsi obtenir des fonctionnalités puissantes d’inférence tout en maîtrisant le besoin en puissance de calcul.
- Assurer la Cohérence : Elles imposent une compréhension et une terminologie communes à travers différentes parties d’un système, ou même entre différents systèmes collaborant.
- Améliorer la Recherche et l’Intégration de Données : Elles facilitent la recherche d’informations précises et la combinaison correcte de données issues de sources différentes.
Pourquoi les ontologies sont-elles particulièrement intéressantes à l’ère des LLM ?
Les Grands Modèles de Langage (LLM), comme ChatGPT, Claude, ou Gemini, sont incroyablement doués pour comprendre et générer du texte. Cependant, ils ont aussi des faiblesses :
- « Hallucinations » : Ils peuvent parfois générer des informations qui semblent plausibles mais sont fausses ou incohérentes.
- Manque de compréhension profonde du domaine : Bien qu’entraînés sur d’énormes volumes de données, ils peuvent manquer des connaissances spécifiques, structurées et nuancées d’un domaine spécialisé comme le droit.
- Problèmes de cohérence : Ils peuvent décrire le même concept juridique différemment à divers moments.
- Explicabilité limitée : Il est souvent difficile de savoir pourquoi un LLM a donné une réponse spécifique.
C’est là que les ontologies deviennent des partenaires extrêmement utiles pour les LLM :
- Ancrer les LLM dans la Réalité (Grounding) : A la manière d’un tuteur qui soutient un arbre, les ontologies peuvent servir de « colonne vertébrale de connaissances » ou de « vérificateur de faits » pour les LLM. En couplant le traitement du LLM à une ontologie structurée représentant des connaissances juridiques fiables, on peut réduire les erreurs et s’assurer que les résultats respectent les faits et les règles établis du domaine.
- Améliorer le Raisonnement Juridique : Les ontologies fournissent des relations logiques explicites que les LLM pourraient ne pas saisir facilement à partir du texte seul. Combiner les capacités linguistiques du LLM avec la structure logique de l’ontologie permet un raisonnement plus robuste et fiable dans un domaine x, par exemple le domaine juridique.
- Augmenter la Cohérence et la Précision : Une ontologie garantit que les concepts et relations du domaine x sont utilisés de manière constante par le LLM, conformément à des définitions pré établies par l’ontologie en question.
- Ajouter de l’Explicabilité : Quand le résultat d’un LLM est guidé ou vérifié par une ontologie, il devient plus facile de retracer le raisonnement jusqu’à la structure sous-jacente, rendant le processus de l’IA plus transparent (explainable AI).
- Intégrer l’Expertise du Domaine : Elles offrent un moyen pratique d’injecter une expertise business pointue et validée dans des systèmes LLM puissants mais généralistes. Cela ouvre la voie à la verticalisation d’agents, par exemple pour des sociétés privées, qui veulent scaler une expertise qui leur est propre (notamment les cabinets juridiques).
En résumé, les ontologies apportent la structure, la cohérence et la base factuelle qui peuvent rendre les LLM plus fiables, précis et dignes de confiance, surtout lorsqu’ils sont appliqués à des tâches complexes et spécialisées (comme dans le droit) au sein de systèmes automatisés. Elles font le pont entre la compréhension large du langage des LLM et la connaissance profonde et structurée requise pour de nombreuses applications du monde réel, et toujours acquise durement par des experts, eux bien humains.
Cas pratique: créons notre propre ontologie
Restons dans le domaine juridique: imaginons que nous voulions représenter des raisonnements juridiques par des ontologies à partir d’arrêts de la Cour de cassation. Voici les étapes de développement que nous aurions besoin de suivre:
- lire le document PDF qui contient l’arrêt de la cour et le charger dans notre programme
- définir un modèle des informations que nous voulons extraire de cet arrêt
- faire lire à un LLM le contenu de cet arrêt pour qu’il en extrait un
structured outputreprenant les champs de notre modèle - passer en paramètre ce
structured outputà une fonction qui créera ou mettra l’ontologie à partir de cet objet formatté - exécuter une autre fonction permettant de visualiser l’ontologie
ingestion du document PDF
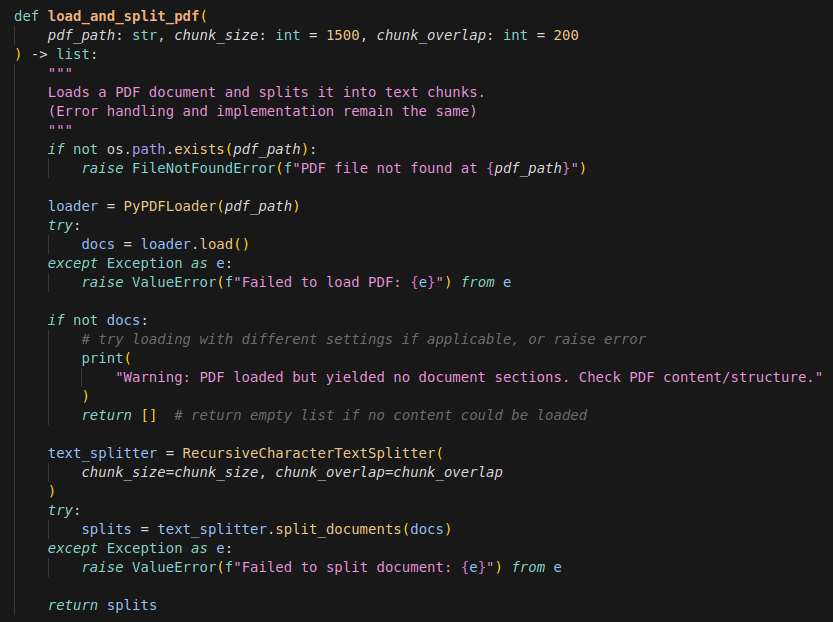
Nous utilisons ici le package langchain-community, qui fournit des méthodes prêtes à l’emploi pour lire et extraire le texte de chaque page d’un document PDF.
définition du modèle de ce que l’on veut faire surfacer d’un arrêt pour notre ontologie
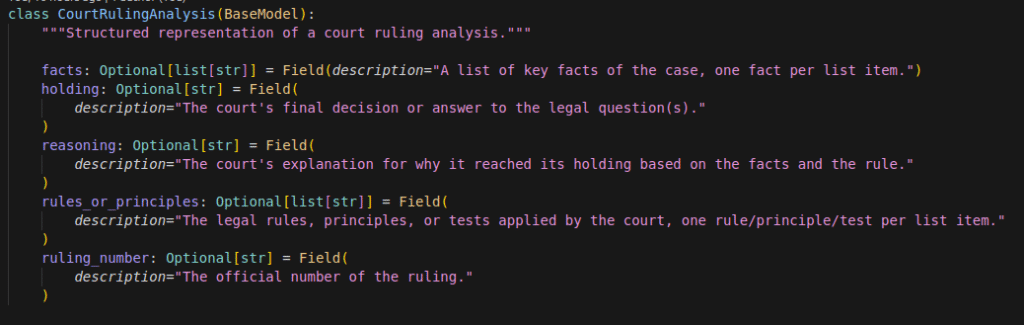
Ici, nous avons décidé qu’il était pertinent de ressortir d’un arrêt:
- les faits (une liste de strings, avec un item par fait)
- la décision finale de la cour
- le raisonnement de la cour
- les principes ou règles juridiques (lois ou autres règlements) appliqués (liste de strings)
- l’identifiant unique de l’arrêt, qui nous servira à discriminer les éléments (les arrêts) de notre ontologie
Génération structurée d’instances de notre modèle en utilisant un LLM
L’idée est ici de:
- donner au LLM notre arrêt en entrée
- le guider dans son extraction avec un prompt via LangChain
- le contraindre à nous donner en sortie un objet dans le format désiré (notre modèle
CourtRulingAnalysis)
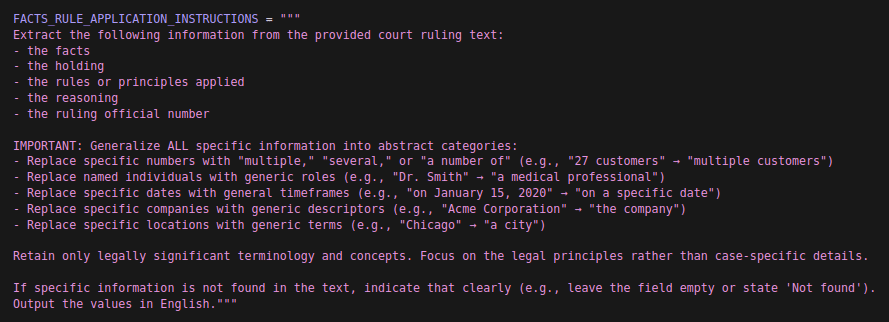
Commençons par ce prompt, le but est ici de reprendre les champs présents dans notre modèle, mais aussi de guider un peu plus le LLM en lui précisant qu’il est intéressant pour nous de tirer des faits et des raisonnements génériques plutôt que les spécificités de l’affaire x ou y.
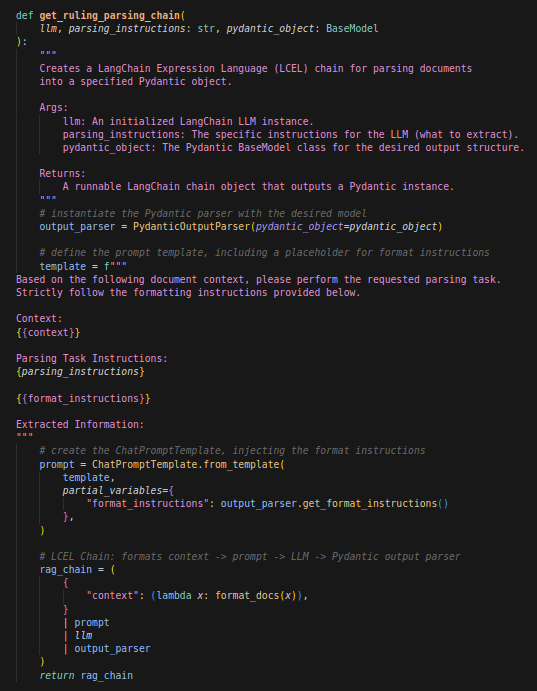
Cette fonction créé une chaîne LangChain qui permet d’appliquer à la fois le prompt que nous avons écrit et le formattage en sortie au moment d’appeler le LLM, la fonction format_docs que vous voyez sert juste à concaténer les pages du PDF de l’arrêt afin que le contexte ne soit pas fragmenté.
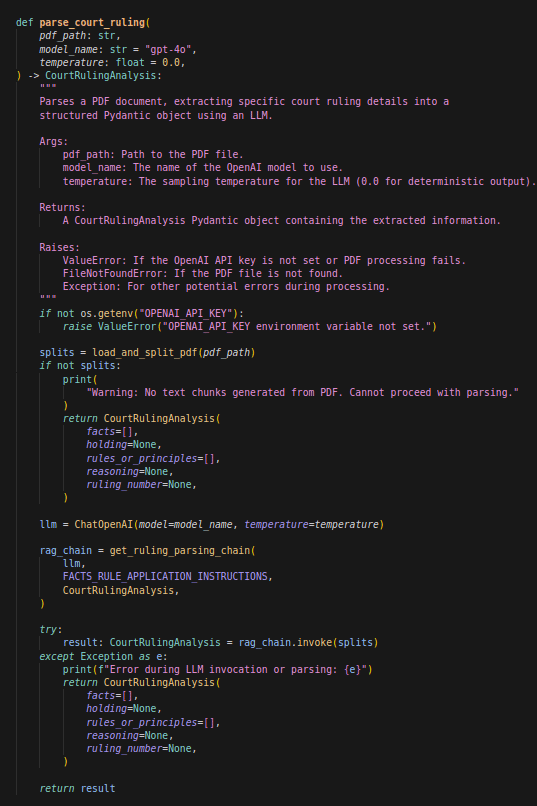
Enfin, nous avons la fonction qui wrap toute cette logique et nous permet de faire toutes les étapes, depuis l’ingestion du document, la concaténation, l’application du prompt, jusqu’à la génération structurée du modèle désiré.
Nous sommes maintenant prêts à passer l’objet retourné à notre méthode qui permettra soit de créer soit de mettre à jour notre ontologie.
Créer ou mettre à jour une ontologie
Nous utiliserons le package owlready2, qui permet de manipuler facilement des ontologies en Python, pour cela. L’idée est la suivante: nous créons une ontologie et la sauvegardons dans un fichier si elle n’existe pas, ou sinon on la met à jour avec un nouvel arrêt si le fichier existe.
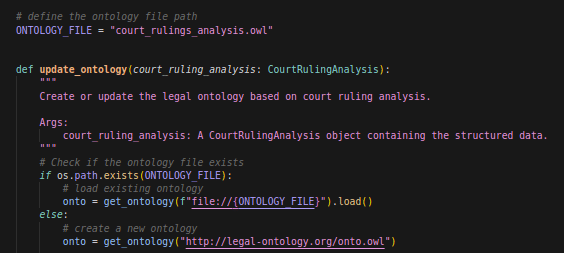
Cette logique de création ou chargement de l’ontologie existante est jouée au début de notre fonction, puis, plus loin dans la même fonction:
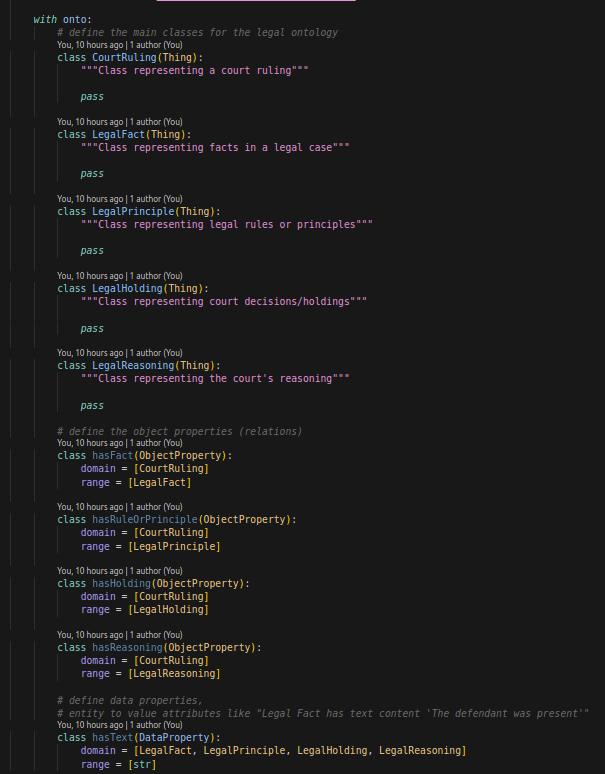
… on définit les concepts (classes) et les relations entre les concepts dans notre ontologie en utilisant la syntaxe fournie par owlready2. Par exemple, nous déclarons qu’un arrêt peut avoir un fait en choisissant arbitrairement le nom de la relation, qui doit toujours commencer par un verbe, pour mieux différencier des concepts composant l’ontologie.
De même, on définit ici aussi les data properties, c’est à dire les attributs du champ x de tel entité; ici, comme on utilise des strings partout, chaque entité a un attribut hasText, tout simplement.
Maintenant que nous avons défini la structure de notre ontologie, nous sommes maintenant prêts, toujours dans la même fonction, à ajouter des items (des arrêts) respectant ce format:
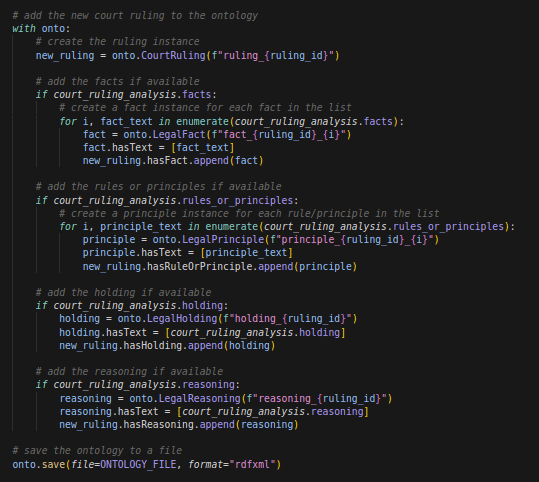
Ici, pour chaque arrêt, on créé une instance de CourtRuling, qu’on hydrate avec les faits, les principes, la décision, et le raisonnement. Enfin nous persistons sur disque notre ontologie. Visualisons maintenant le résultat !
Visualisation de l’ontologie
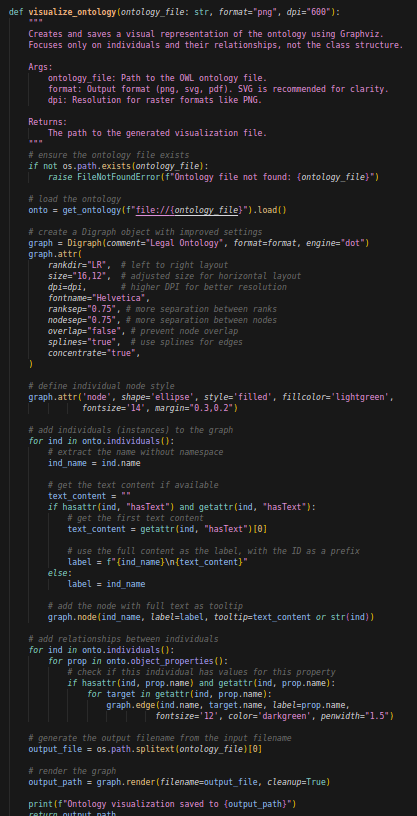
Cette fonction utilise la librairie Python graphviz (dont les dépendances doivent aussi être installées sur votre système) pour créer une visualisation, sous la forme d’un directed graphe partant de la gauche vers la droite, de notre ontologie. Si votre résultat est pixellisé, pensez à augmenter les dpi. Cela nous donne, par exemple, le résultat suivant:
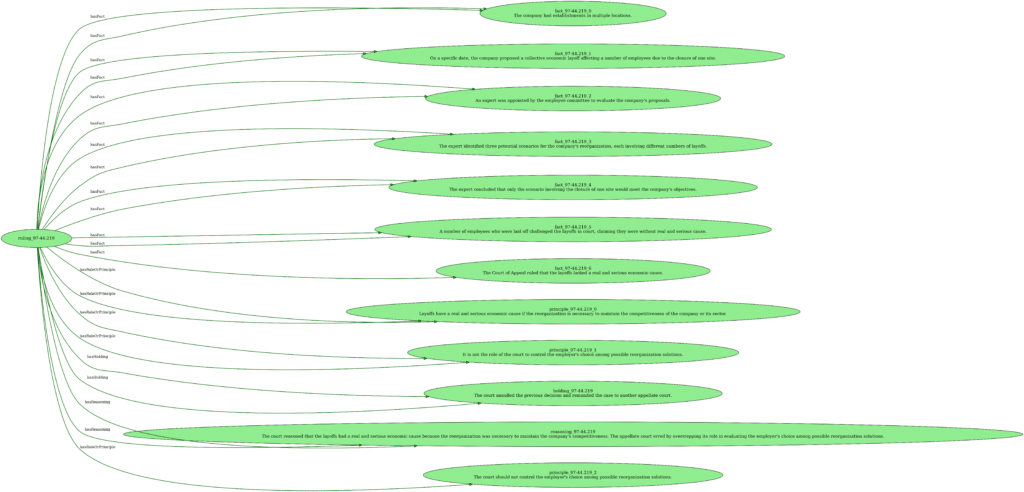
On a ainsi une représentation qui est:
- visuelle, aidant ainsi à la compréhension des humains
- formattée et sujette à inférence avec une machine
Qu’est-ce que nous pouvons faire maintenant ?
Maintenant que nous avons onboardé sur la création et la visualisation d’ontologies en utilisant des LLMs, voici quelques applications pratiques et concrètes sur lesquels nous pourrions nous aventurer, armés de ce nouveau savoir.
Notre ontologie juridique capture les relations entre la jurisprudence, les faits, les principes, les motifs décisionnels et le raisonnement. Nous pourrions apporter une réelle valeur ajoutée avec ce genre de features:
- Recherche juridique basée sur les précédents
- Analyse de similarité des cas : Trouver des affaires présentant des faits similaires à un problème juridique actuel.
- Cartographie des principes juridiques : Suivre comment des principes juridiques spécifiques ont été appliqués dans différentes affaires.
- Identification des décisions contradictoires : Découvrir des cas où des faits similaires ont conduit à des issues différentes.
- Aide au raisonnement juridique
- Construction d’arguments : Élaborer des arguments juridiques en identifiant les affaires où des principes spécifiques ont prévalu.
- Analyse des schémas de raisonnement : Identifier les schémas de raisonnement courants utilisés par les juges pour des types spécifiques d’affaires.
- Anticipation des contre-arguments : Prédire les arguments de la partie adverse en se basant sur les schémas historiques.
- Formation et enseignement juridiques
- Enseignement par études de cas : Créer des études de cas interactives montrant les relations entre les faits, les principes et les issues.
- Visualisation du raisonnement juridique : Aider les étudiants en droit à comprendre comment les faits se connectent aux principes juridiques.
- Évaluation des connaissances : Créer des systèmes pour tester la capacité des étudiants à appliquer des principes à de nouvelles situations factuelles.
- Analyse juridique prédictive
- Prédiction de l’issue des affaires : Prédire les issues probables des affaires en analysant des faits similaires et les principes appliqués.
- Analyse des tendances des juges/tribunaux : Identifier comment des tribunaux spécifiques ont tendance à interpréter certains principes juridiques.
- Évaluation du risque juridique : Évaluer le risque lié à un litige en trouvant des affaires similaires et leurs issues.
- Gestion des connaissances juridiques
- Préservation des connaissances institutionnelles : Capturer et organiser les connaissances et raisonnements juridiques spécifiques à un cabinet.
- Localisation de l’expertise : Identifier quels avocats possèdent une expérience sur des principes juridiques spécifiques.
- Identification des lacunes dans les connaissances : Découvrir les domaines où la jurisprudence est limitée ou contradictoire.
- Optimisation des processus juridiques
- Aide à la rédaction de mémoires/conclusions : Faire émerger les affaires et principes pertinents lors de la préparation des écrits.
- Cartographie de la conformité réglementaire : Relier les réglementations à leurs interprétations judiciaires.
- Développement de stratégies juridiques : Soutenir la prise de décision stratégique en explorant les pistes d’argumentation potentielles.
- Applications interdisciplinaires
- Analyse de l’impact des politiques : Évaluer comment les interprétations judiciaires affectent la mise en œuvre des politiques.
- Recherche juridique académique : Soutenir les études empiriques sur la prise de décision judiciaire.
- Analyse de droit comparé : Comparer comment des principes similaires sont appliqués dans différentes juridictions.
- Applications avancées d’IA juridique
- Grounding des LLM : Utiliser l’ontologie pour ancrer les réponses des grands modèles de langage (LLM) dans la jurisprudence réelle.
- IA juridique explicable : Créer des systèmes d’IA capables d’expliquer leur raisonnement en référence à des affaires établies.
- Compréhension du langage juridique : Améliorer le traitement automatique du langage naturel (TALN) spécifique au domaine juridique en fournissant des connaissances structurées.
Chacune de ces applications exploiterait les connaissances structurées et les relations capturées par notre ontologie, permettant une analyse plus sophistiquée que de simples recherches textuelles ou des approches non structurées.
Plus qu’un simple formatage, une ontologie permet aussi la recherche (avec un système de requêtage présent dans les principales libs), la visualisation, l’inférence et le grounding des LLMs, c’est donc un outil très puissant qui peut être appliqué à bien d’autres domaines !

