
Tokens et ordres de grandeur
La plupart des meilleurs LLMs, à l’exception notable de Gemini 1.5 et de ses incroyables 2 millions de tokens de contexte, plafonnent à 128K tokens de contexte, et ce aussi bien pour les LLMs ouverts que pour les modèles en closed-source.
Pour vous donner un ordre d’idées, 128K c’est environ:
- 123 questions sur Stack Overflow et leurs réponses
- 300 pages de pur texte (une nouvelle en langue Anglaise)
- 1680 tweets
… c’est impressionnant, mais là on parle uniquement de contenu texte brut. Si on devait donner une page HTML en input à un LLM qui supporte ce genre de long contexte, on perdrait beaucoup au change, par exemple:
- un article de Wikipédia tiré du web et donné directement à un LLM utiliserait à lui seul ~42K tokens (soit 33% de la capacité théorique)
- une SERP (page de résultats de recherche de Google) donnée telle quelle à un LLM utiliserait un contexte d’environ 250K tokens (du fait des scripts, de la métadonnée, etc. dont sont bourrées ces pages)
Ce qu’il faut retenir de cela, c’est que la forme compte tout autant que le fond en ce qui concerne la gestion de contexte de votre LLM.
Distinction entre les types de tâches
Jusque là, nous avons considéré uniquement la capacité théorique en matière de contexte. Il faut toutefois savoir que:
- les LLMs perdent en performance à mesure que le contexte grandit, car le mécanisme d’attention qui les fonde se retrouve mis à rude épreuve lorsqu’il s’agit de prioriser et de retenir l’information la plus pertinente lorsque le contexte est très long (ce problème est appelé « lost in the middle »)
- l’effort herculéen que l’on demande aux LLMs lors de nos tâches quotidiennes est en réalité en 2 dimensions:
- tâches consistant à simplement récupérer de l’information, telle quelle, dans un long contexte: c’est surtout dans ce domaine qu’il y a eu les plus grosses avancées et que les LLMs présentent des performances consistantes (qu’ils soient privés ou open); Gemini est le champion dans ce domaine
- tâches impliquant beaucoup de raisonnement: gourmandes en ressources et complexes, on constante, qu’avec la plupart des LLMs long-contexte, les performances en la matière se dégradent au bout à partir de 16K ou 32K tokens, voire moins (en fonction du modèle)
- enfin, plus le contexte est long, plus la réponse à générer sera produite lentement car le coût en termes de ressources de calcul sera plus élevé
Ainsi, on va se retrouver avec des cas où les LLMs vont répéter du contenu aléatoire, générer des réponses peu pertinentes, simplement résumer le contexte qui leur est donné au lieu de répondre à la question de l’utilisateur, etc. Vous pouvez essayer vous-même en ouvrant une nouvelle conversation avec Claude ou ChatGPT et la faire durer très longtemps ! Je suis certain que votre capacité à raisonner sur de longs contextes sera plus élevée que celle du bot… => petit clin d’oeil aux doomers qui pensent qu’on va tous se faire remplacer 😉, le travail de l’esprit humain a encore de beaux jours devant lui !
Conseils pratiques et checklist
- Comme depuis toujours en Data Science et Deep Learning, la pré traitement de vos données est essentielle:
- avez-vous enlevé tout contenu inutile de votre input (exemple des métadonnées et scripts divers des pages HTML) ?
- avez vous lemmatizé le contenu ? La lemmatization est un procédé qui consiste à ramener un mot à sa forme de base, indépendamment de ses variations grammaticales, par exemple amener un verge conjugé à l’infinitif. Des librairies Python telles que NLTK vous permettent de faire cela facilement.
- De même, posez-vous la question, en ce qui concerne la performance attendue du LLM que vous utilisez: suis-je en train de faire du simple Q&A sur un volume x de données ? ou bien dois-je utiliser mon LLM pour des tâches impliquant plus de raisonnement ? La réponse à ces questions vous fera aborder les questions de gestion de contexte différemment, car vous aurez un contexte beaucoup plus court à votre disposition si vous êtes dans le cas de tâches de raisonnement.
- Suis-je dans un cas où j’ai besoin d’une réponse immédiate du LLM (use-case conversationnel classique) ou bien dois-je exécuter des tâches de post ou pré processing au long cours utilisant des LLMs, et pour lesquelles l’instantanéité n’est pas un pré requis? Cette question vous aidera aussi à choisir le bon modèle en fonction de votre besoin.
Exemple de gestion de contexte: use-case conversationnel avec Llama3.1
Rassurez-vous, je ne vais pas vous laisser qu’avec des problèmes de contexte à gérer, laissez-moi vous apporter une solution parmi d’autres ! 🙂
Nous allons utiliser LangChain et LangGraph pour mettre en oeuvre le procédé suivant:
- on initie un simple graphe de conversation avec Llama3.1
- passé un certain nombre de tokens utilisé dans la conversation, on déclenche une logique qui va:
- résumer toute la conversation précédente en utilisant le même LLM
- ré injecter ce résumé dans la conversation
- supprimer les autres messages afin de réduire le contexte, en ne gardant que le résumé de la conversation et le dernier message de l’utilisateur
- continuer la conversation
Si vous ne savez pas du tout utiliser LangChain et LangGraph, pas de panique, de nombreuses ressources existent sur le Net pour vous former, notamment l’excellente chaîne YouTube de LangChain, qui parcourt de nombreux cas d’usage sur les applications agentiques.
Pour cet example, j’ai choisi d’utiliser llama3.1:8b car:
- il peut run sur des machines consumer-grade en privé
- il supporte 128K tokens de contexte en théorie, mais ses performances se dégradent progressivement au bout de 8K tokens, jusqu’à devenir peu utilisable à 96K tokens; c’est une illustration parfaite de la problématique que nous abordons
Imaginons ici que nous voulions garder une performance optimale, en matière d’expérience utilisateur, avec ce modèle => nous allons donc veiller à ce que le contexte ne dépasse jamais ~ 8K tokens.
Commençons par invoquer les dépendances nécessaires et créer le noeud de base de notre graphe LangGraph: celui appelant le LLM.
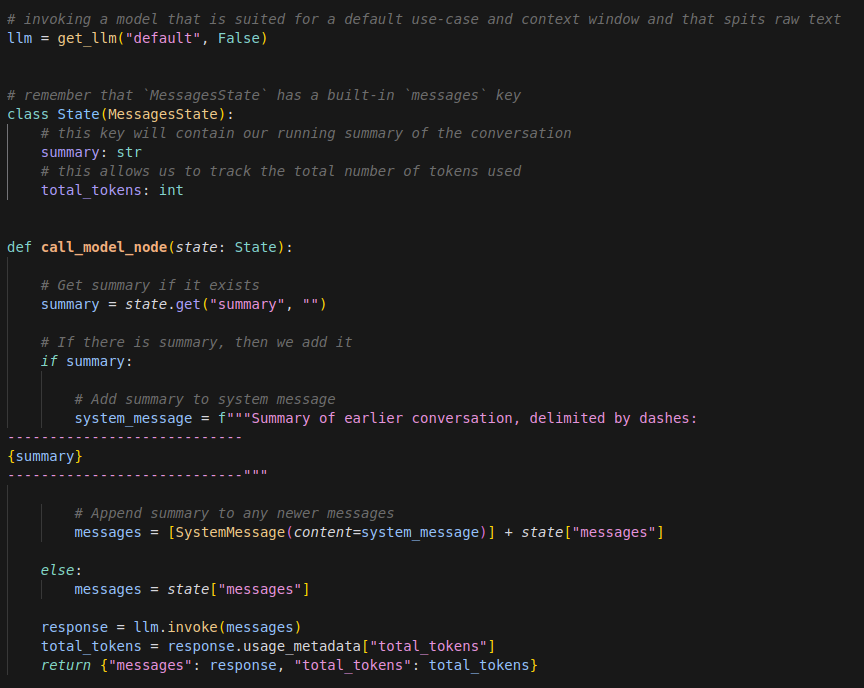
Ce simple noeud contient déjà toutefois la logique suivante:
- si un résumé existe dans l’état du graphe courant, il est ajouté à la liste des messages de la conversation
- le nombre de tokens consommés (qu’ils soient entrants ou sortants) est mis à jour à chaque round de la conversation impliquant le LLM
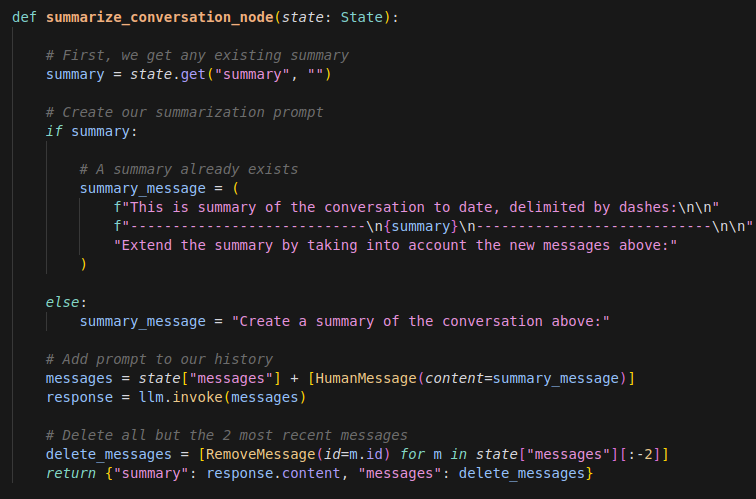
Maintenant, définissons le noeud qui va:
- générer le résumé de la conversation en utilisant le même LLM (on pourrait d’ailleurs en utiliser un autre, plus performant dans des tâches de récupération et résumé de contenu pour cette tâche)
- supprimer tous les messages de la conversation sauf 2: le résumé de la conversation jusque là, la dernière interaction de l’utilisateur
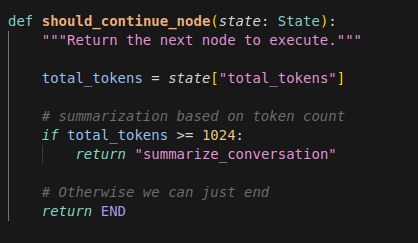
Enfin, mettons en place le noeud charnière, celui qui va créer le résumé dès lors que la conversation dépasse un certain nombre de tokens (nous avons pris ici la valeur de 1024K tokens au lieu de 8000 ou moins afin de pouvoir run l’exemple sans avoir à créer une conversation trop longue):
Maintenant, nous sommes en mesure de construire notre graphe:
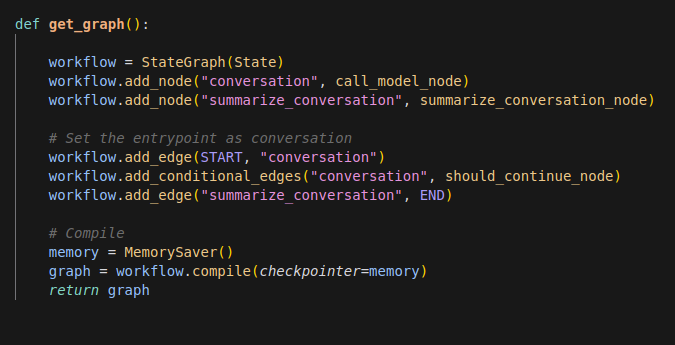
… à noter ici l’utilisation d’un memory checkpointer, qui permet de garder une persistence de l’état du graphe lors de l’exécution du programme.
Voici une représentation de notre graphe:
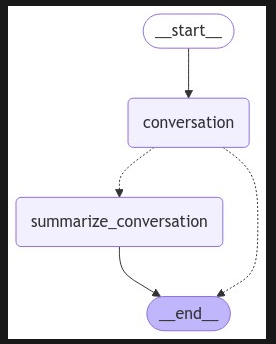
Nous pouvons maintenant l’exécuter la manière suivante:
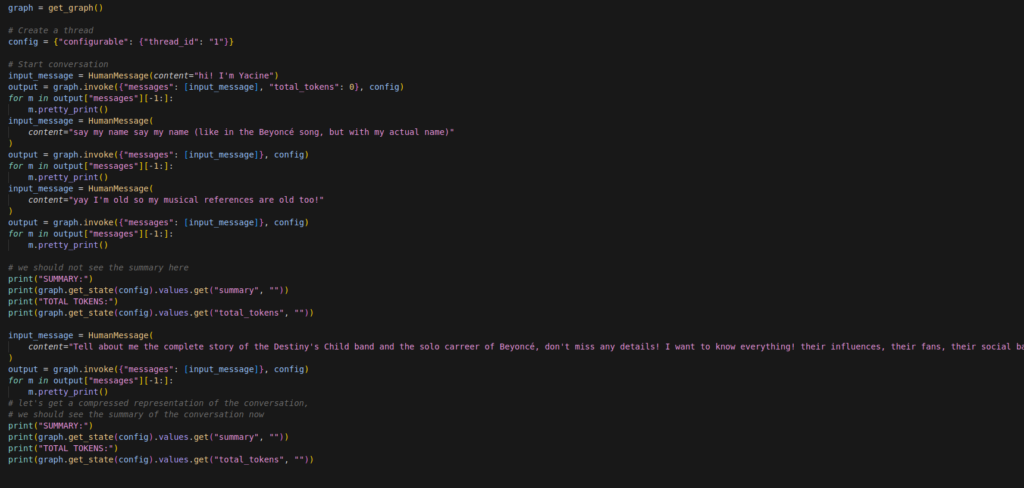
Ici, dans un premier temps, je chat avec Llama3.1 et la fonctionnalité de création de résumé n’est pas activée sur les trois premiers messages, comme on le voit ici:

… mais à partir du moment où je lui demande de générer du long contenu (ici un résumé de la carrière des Destiny’s Child et de Beyoncé), il se passe la chose suivante:
- un résumé de la conversation est créé
- les anciens messages sont supprimés de la conversation, au profit du résumé
- nous affichons aussi les tokens consommés au total
Vous avez ici l’énorme réponse contenant l’histoire de la carrière de Beyoncé:
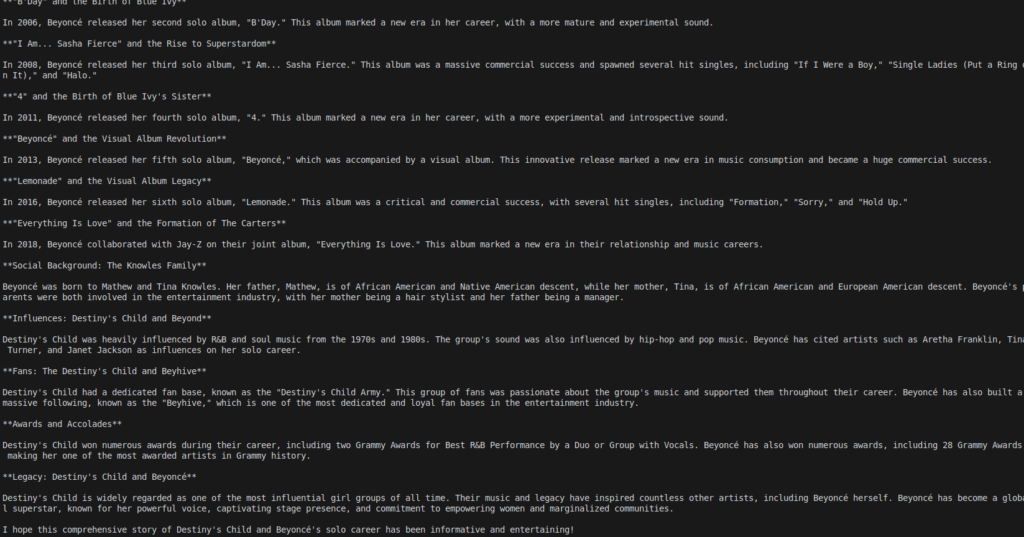
… mais après cela, notre fonction de génération de résumé à kick in et on se retrouve avec ce texte beaucoup plus court =>
Here's a summary of our conversation:
We had a fun conversation about Destiny's Child and Beyoncé's solo career. I provided a detailed history of the group, including their formation in 1990, early success with albums "Destiny's Child" (1998) and "The Writing's on the Wall" (1999), lineup changes, and eventual disbandment.
I also delved into Beyoncé's solo career, highlighting her debut album "Dangerously in Love" (2003), subsequent albums "B'Day" (2006), "I Am... Sasha Fierce" (2008), "4" (2011), and "Beyoncé" (2013). We discussed her visual album releases, including "Beyoncé" (2013) and "Lemonade" (2016).
We touched on Beyoncé's social background, influences, and fans, as well as her numerous awards and accolades. I also mentioned the Knowles family, Destiny's Child's dedicated fan base (the "Destiny's Child Army"), and Beyoncé's massive following (the "Beyhive").
Overall, our conversation provided a comprehensive overview of Destiny's Child and Beyoncé's solo career, covering their music, legacy, and impact on the entertainment industry.Si je continuais ma conversation avec le bot, bien que nos interactions aient consommé 1677 tokens en quatre questions/réponses (j’ai vérifié), ce sera le résumé qui sera injecté dans le contexte à partir de là, après suppression des anciens messages.
Nous nous retrouvons dès lors avec une conversation toute fraîche de 256 tokens seulement 🥬 (j’utilise un emoji de laitue parce que c’est le premier truc frais auquel j’ai pensé) et nous pouvons garder une peak performance avec notre petit Llama3.1 8B 🚀
Nous avons mis en oeuvre une technique simple de compression de contexte de cette manière, mais il en existe beaucoup d’autres !
Reboot aime LangChain et les applications agentiques !
Nous avons écrit plusieurs articles sur cette stack fascinante qu’est LangChain dans ce blog, n’hésitez pas à y jeter un oeil 👀:
- test-drive de LangChain
- l’écosystème LangChain
- prise en main de LangServe
- introduction au pattern ReAct avec LangGraph
- créer un générateur d’articles avec LangGraph
A très bientôt ! 👋

