
Dans un monde où l’automatisation et l’intelligence artificielle prennent de plus en plus d’importance, la génération de contenu automatisée est devenue un sujet brûlant. LangGraph de LangChain offre une solution innovante pour créer des articles de haute qualité en utilisant plusieurs agents d’IA spécialisés. Cet article vous guidera à travers la création d’un générateur d’articles en Python en utilisant LangGraph, en fournissant des extraits de code, des explications détaillées et des décisions de concepts clés. Nous aborderons également les implications éthiques et l’importance de la supervision humaine.
🔍 Introduction à LangGraph et LangChain
LangGraph est une bibliothèque conçue pour créer des applications multi-agent avec état, utilisant des LLMs. Elle permet de définir des flux impliquant des cycles, ce qui est essentiel pour la plupart des architectures agentiques. LangChain, quant à lui, est un framework qui simplifie chaque étape du cycle de vie des applications LLM, de la conception à la mise en production. Ensemble, ces outils offrent une solution robuste pour le développement d’applications basées sur l’IA. Pour les débutants, LangGraph permet de structurer les tâches de manière modulaire, tandis que LangChain facilite l’intégration et la gestion des modèles de langage.
🛠️ Conception du Générateur d'Articles
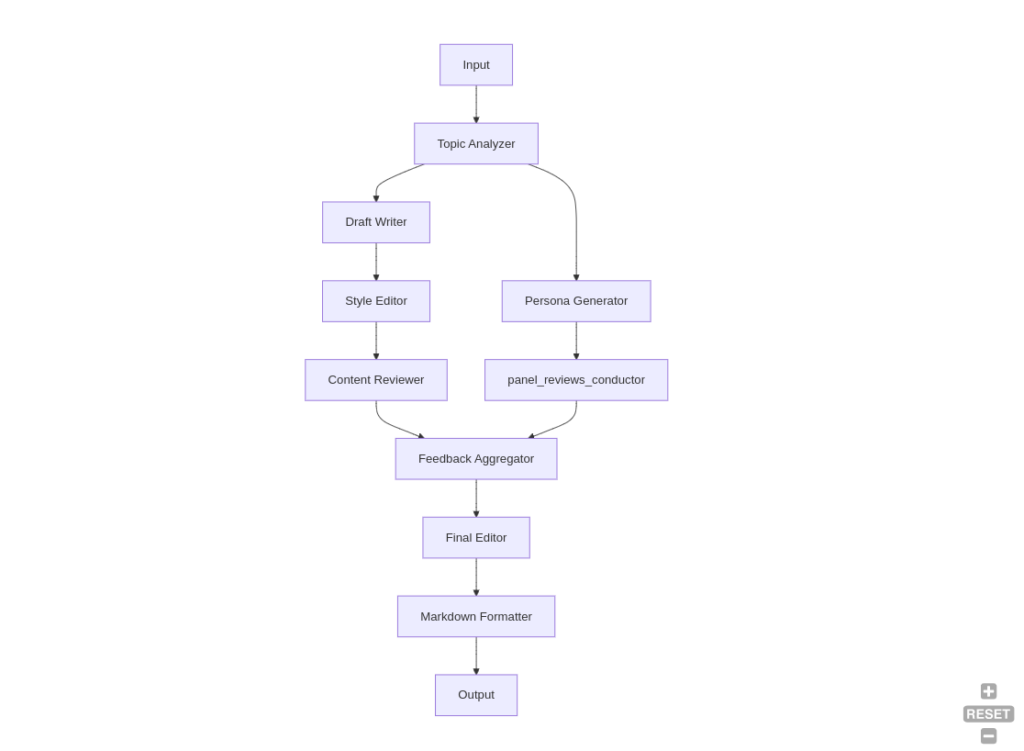
La conception de notre générateur d’articles repose sur une structure modulaire, où chaque tâche est représentée par un nœud distinct dans un graphe. Cette approche permet une flexibilité et une évolutivité accrues. Voici les principaux composants de notre générateur d’articles :
- Analyseur de Sujet : Analyse le sujet donné et génère un plan
- Générateur de Persona : Crée un panel de relecteurs ciblant le public visé
- Rédacteur de Brouillon : Rédige le brouillon initial de l’article
- Éditeur de Style : Revoit et édite l’article pour le style et le ton
- Relecteur de Contenu : Évalue la qualité et la pertinence du contenu
- Agrégateur de Feedback : Collecte et résume les retours des relecteurs
- Éditeur Final : Intègre les retours et produit la version finale
- Formateur Markdown : Convertit l’article final en format Markdown pour la sortie
Pour illustrer, imaginons que nous voulons créer un article sur les tendances de l’IA en 2023. L’analyseur de sujet identifiera les sous-thèmes pertinents, le générateur de persona définira les profils des lecteurs potentiels, et ainsi de suite, jusqu’à la production de l’article final.
🚀 Étapes de Mise en Œuvre
Pour implémenter notre générateur d’articles, nous suivrons les étapes suivantes :
- Initialisation des Nœuds : Commencez par initialiser les nœuds nécessaires. Par exemple, le nœud Topic Analyzer est initialisé avec un modèle de langage pour analyser le sujet.
class TopicAnalyzerConfig(NodeConfig):
required_fields: List[str] = ["user_input"]
class TopicAnalyzer(BaseNode):
def __init__(self, config: NodeConfig = TopicAnalyzerConfig(), llm: BaseLLM = None):
super().__init__(config)
if not llm:
raise ValueError("No language model provided for topic analysis")
self.llm = llm
def process(self, state: Dict[str, Any]) -> Dict[str, Any]:
logger.info("Analyzing topic")
user_input = state['context'].get('user_input')
if not user_input:
raise ValueError("No input provided for analysis")
chain = (topic_analysis_prompt
| self.llm.with_config(response_format={"type": "json"})
| SimpleJsonOutputParser())
analysis = chain.invoke({"input": user_input})
state['context'].topic_analysis = TopicAnalysisOutput.model_validate(analysis)
return state
2. Création du Graph : Ajoutez les nœuds au graph et définissez les connexions entre eux.
graph.add_node("topic_analyzer", topic_analyzer.process)
graph.add_node("persona_generator", persona_generator.process)
graph.add_node("draft_writer", draft_writer.process)
graph.add_edge("topic_analyzer", "persona_generator")
graph.add_edge("topic_analyzer", "draft_writer")
3. Définition des Prompts : Utilisez des templates de prompts pour guider les modèles de langage dans leurs tâches respectives.
topic_analysis_prompt = PromptTemplate(
input_variables=["input"],
template="""Vous êtes un stratège de contenu expérimenté
chargé d'analyser les sujets d'articles et de fournir des
<insights aux rédacteurs. ..."""
)
4. Traitement des Erreurs : Implémentez des mécanismes de gestion des erreurs pour chaque nœud afin d’assurer la robustesse du système.
if not user_input:
raise ValueError("No input provided for analysis")
5. Compilation et Exécution : Compilez le graph et exécutez-le pour générer l’article final.
graph.compile(checkpointer=memory)
🧩 Concepts Clés et Décisions
Notre générateur d’articles repose sur plusieurs concepts clés :
- Modularité : Chaque nœud représente une tâche spécifique, permettant une modification ou un remplacement facile des composants individuels.
- Cycles et Boucles : LangGraph permet d’implémenter des cycles et des boucles, essentiels pour les architectures agentiques.
- Génération de Persona : Le nœud Persona Generator crée un panel de reviewers ciblant le public visé.
- Processus de Révision : Les étapes de révision séquentielles (Style Editor, Content Reviewer, Feedback Aggregator) assurent une évaluation approfondie de l’article.
- Scalabilité : Des étapes de révision supplémentaires ou des agents spécialisés peuvent être facilement ajoutés au graph si nécessaire.
Ces concepts assurent que notre générateur d’articles est non seulement efficace mais aussi adaptable à divers scénarios et besoins.
⚠️ Défis Potentiels et Solutions
Lors de la mise en œuvre d’un générateur d’articles, plusieurs défis peuvent survenir :
- Gestion de la qualité du contenu : Utiliser des algorithmes de fact-checking pour vérifier l’exactitude des informations.
- Réactivité aux retours : Intégrer des boucles itératives pour améliorer le contenu basé sur les retours des utilisateurs.
- Biais dans les modèles de langage : Mettre en place des méthodes pour identifier et atténuer les biais, comme l’analyse de la diversité des sources et des perspectives.
🧠 Considérations Éthiques et Biais Potentiels
L’utilisation de modèles de langage pour générer du contenu soulève des questions éthiques importantes. Les biais présents dans les données d’entraînement peuvent se refléter dans les articles générés. Il est crucial de mettre en place des mécanismes pour identifier et atténuer ces biais. Par exemple, en diversifiant les sources de données et en incluant des perspectives variées, on peut réduire le risque de biais systématiques.
🔧 Extensions et Améliorations Futures
Bien que notre générateur d’articles soit efficace, il peut être amélioré en ajoutant des fonctionnalités telles que la réactivité aux feedbacks (ReAct pattern) et des boucles itératives pour une amélioration continue. Par exemple, nous pourrions ajouter des nœuds supplémentaires pour gérer la vérification des faits et itérer sur les retours des relecteurs pour affiner l’article. De plus, l’intégration avec des systèmes existants, comme des CMS ou des plateformes de publication, pourrait être explorée pour une automatisation complète du flux de travail.
🏁 Conclusion
En utilisant LangGraph, nous avons créé un générateur d’articles modulaire et évolutif en Python. Cette approche permet de produire des articles de haute qualité de manière automatisée, tout en offrant la flexibilité nécessaire pour intégrer des améliorations futures. En suivant les étapes décrites dans cet article, vous pouvez développer votre propre générateur d’articles et tirer parti des puissantes capacités des LLMs pour la création de contenu. N’oubliez pas d’intégrer des mécanismes de gestion des erreurs et de prévoir des améliorations continues pour maintenir la pertinence et la qualité de vos articles.
* Cet article a été généré par une intélligence artificielle

