Cet article fait partie de la série d’articles sur scikit-learn, il fait suite à l’article sur la cross-validation que je vous invite à lire avant de lire celui-ci. Nous nous baserons sur les concepts et codes abordés dans l’article sur la cross-validation pour les approfondir.
Recherche hyperparamétrique : Qézaco ?
Dans les articles précédents, nous avons vu comment optimiser l’entraînement d’un modèle, une forêt aléatoire pour un jeu de données spécifique. Mais si on s’attarde un peu sur la documentation de la forêt aléatoire de scikit-learn, on voit qu’on aurait pu changer plusieurs paramètres de cette forêt. Que se passerait-il si on modifiait le nombre d’arbres, est-ce que cela impacterait nos prédictions ? Et si les arbres sont plus complexes, que se passera-t-il ? Et si chaque arbre ne traitait qu’un pourcentage des données ? Pour répondre à toutes ces questions, il faudrait tester différents modèles de forêts aléatoires et les configurer de manière différente, puis comparer leurs performances respectives.
Faire cette étude des paramètres (qu’on appelle des « hyperparamètres ») des modèles, c’est ce qu’on appelle une recherche hyperparamétrique. Le but de celle-ci est de trouver une configuration optimale du modèle pour le problème que l’on souhaite résoudre en trouvant une combinaison d’hyperparamètres plus efficace que les autres. À noter que cette configuration peut être un optimal local, car il peut y avoir une telle quantité de combinaisons que toutes les tester prendraient trop de temps.
Quelle marche à suivre pour cette recherche ?
Comment opérer une telle recherche ? Une fois l’algorithme du modèle choisi, il y a 3 étapes essentielles à suivre.
Premièrement, il faut choisir les combinaisons d’hyperparamètres que nous voulons optimiser et quelles valeurs peuvent prendre ces paramètres. En effet, il faut limiter le champ de recherche des hyperparamètres pour que la recherche puisse finir d’une part, mais aussi pour éviter de rechercher volontairement des combinaisons farfelues ou qui ne seront pas exploitables par la suite.
Deuxièmement, il faut diviser le jeu de données en 2 parties, le jeu d’entraînement et celui de validation. Dans une recherche hyperparamétrique, nous allons effectuer une validation croisée pour réduire les biais d’entraînement liés à l’overfitting des modèles, mais pour comparer les modèles proposés entre eux de manière objective, il faut que la comparaison finale des modèles se fasse sur des données qu’ils n’ont jamais vues. Le jeu de validation sert précisément à ceci. Le jeu d’entraînement servira donc de jeu d’entraînement de chaque modèle, mais aussi de test pour chaque entraînement.
Troisièmement, une fois tous les modèles entraînés et les modèles testés sur le jeu de validation, il faut comparer les résultats obtenus et choisir la meilleure option, basée sur la métrique de son choix.
Notre recherche est maintenant terminée, nous avons notre meilleur modèle. Nous pouvons soit utiliser ce modèle, soit encore affiner la recherche.
Pratique avec scikit-learn
Avant de passer à la pratique avec scikit-learn, reprenons le modèle et le jeu de données de l’article précédent : la forêt aléatoire avec le dataset l’Adult Census Income. Cela nous permettra d’être plus familiers avec les données et de garder le même objectif : prédire si les personnes ont un revenu de plus de $50k ou non.
Voici le code :
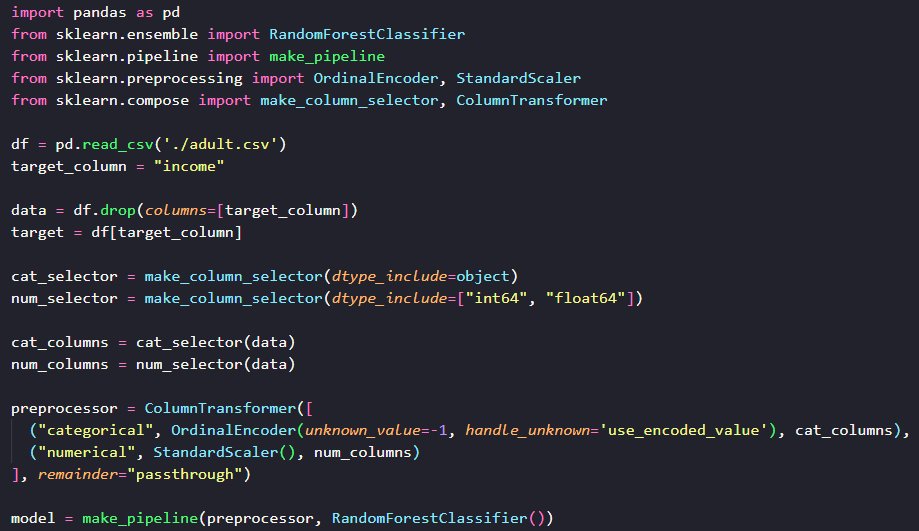
Pour une explication de ce code, référez-vous aux articles précédents sur scikit-learn. Maintenant qu’on a notre modèle, comment faire cette recherche ? On suit notre plan ! Première étape : choisissons les hyperparamètres du modèle sur lesquels nous voulons influer.
Sélectionner les hyperparamètres
Pour savoir quels sont les hyperparamètres de notre modèle, et surtout comment ils sont nommés, scikit-learn nous fournit la méthode get_params. Cette méthode nous retourne tous les paramètres que nous pouvons modifier et leur valeur actuelle.
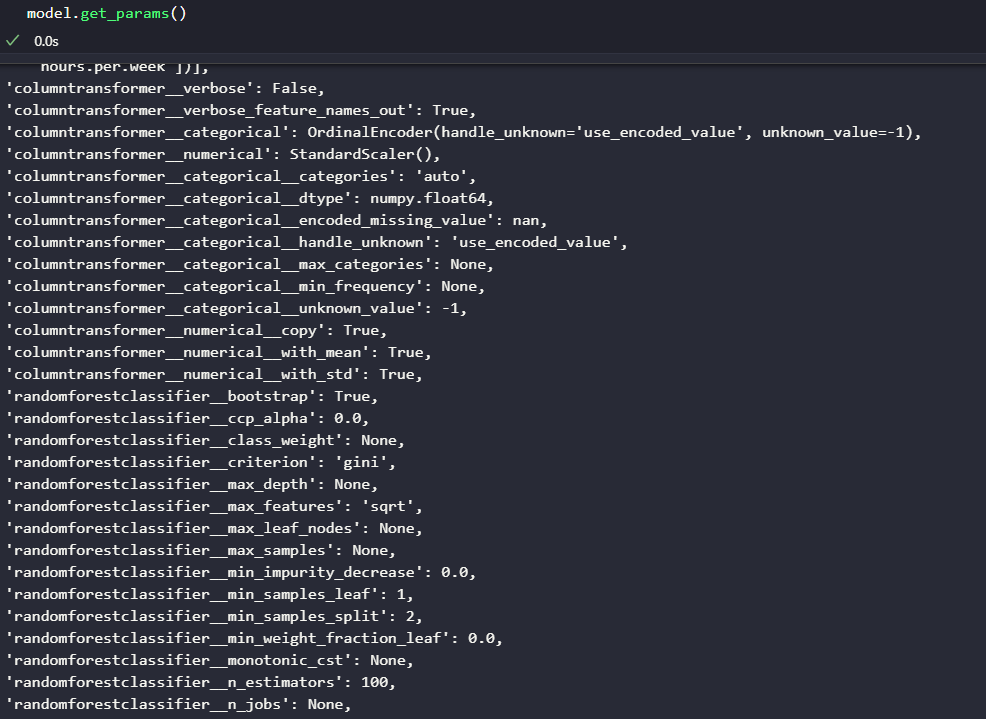
Comme vous pouvez le voir, notre modèle a beaucoup d’hyperparamètres. Il y a 2 raisons à ça : premièrement, les forêts aléatoires possèdent plusieurs aspects sur lesquels nous pouvons influer. Secondement, notre modèle est composé de plusieurs parties, car il transforme les données de notre dataset, puis fait sa prédiction. Naturellement, on peut aussi influer sur les paramètres de cette transformation de données, mais ce n’est pas le but ici.
Concernant le nom de ses hyperparamètres, il dépend du nom des classes qui composent le modèle, mais aussi des noms qu’on peut lui donner. Ce nommage se fait quand on crée le pipeline et ses composants. Ce n’est pas le sujet de cet article, mais voici la documentation qui explique cette partie.
Pour cet article, nous allons choisir 3 paramètres que nous souhaitons combiner et optimiser :
randomforestclassifier__n_estimators: c’est le nombre d’arbres de décisions dans notre forêt aléatoire. C’est une valeur entière.randomforestclassifier__max_depth: c’est la profondeur maximale de chaque arbre. Plus un arbre est profond, plus il s’adaptera aux détails du jeu d’entraînement, le rendant plus performant, mais aussi plus prone à de l’overfitting. C’est une valeur entière.randomforestclassifier__max_samples: c’est la proportion de données que chaque arbre pourra voir au max. Cette valeur est comprise entre 0 et 1 dans notre exemple.
Il en existe évidemment d’autres, je vous renvoie vers la documentation de scikit-learn sur les RandomForestClassifier si vous voulez approfondir votre recherche.
Maintenant, il nous faudra juste trouver les valeurs que nous voulons tester et faire la recherche, mais comment s’y prendre ? Une méthode simple serait de faire des boucles for sur les valeurs que nous voulons tester. Mais scikit-learn fournit des outils plus puissants que ça, et c’est ce que nous allons utiliser.
Recherche par grille
Le premier type de recherche que nous allons utiliser est la recherche par grille, le Grid Search. Le principe de la recherche par grille va être de tester toutes les combinaisons de valeurs possibles parmi celles qu’on va lui donner. Par exemple, dans notre cas, il va tester les 3 paramètres avec les différentes valeurs que nous allons lui renseigner. Donc, si on renseigne 5 valeurs différentes par paramètre, il va créer 5 * 5 * 5 = 125 combinaisons différentes.
La recherche par grille est donc exhaustive et sa complexité combinatoire augmente très vite. En contrepartie, aucune option n’est laissée non testée. Et donc, avec scikit-learn, comment on fait ? Comme souvent, nous avons une classe pour ça : sklearn.model_selection.GridSearchCV. Pour l’utiliser, nous allons d’abord définir un dictionnaire qui va contenir les paramètres et les différentes valeurs que nous allons tester.
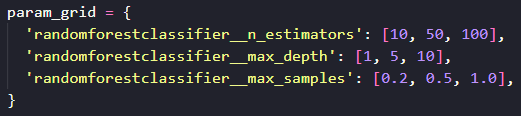
Comme vous pouvez le voir, les clés de ce dictionnaire sont les paramètres que la méthode get_params() nous a donnés. Les valeurs sont des listes de valeurs que nous voulons tester. Ici notre but est clairement de découvrir comment ces paramètres influent les résultats. L’étendue de certaines valeurs est volontairement large.
Ensuite nous allons utiliser GridSearchCV. Pour cela, rien de plus simple, on lui passe notre modèle, la grille de paramètres, la métrique qu’on veut utiliser et les cross-validations que l’on veut faire et c’est tout !

Et oui, la recherche hyperparamétrique utilise aussi la validation croisée, cela permet de fiabiliser les résultats. Ce paramètre cv fonctionne d’ailleurs comme celui de la fonction cross_validate qu’on a vu dans l’article sur la validation croisée.
Une fois l’objet créé, il faut utiliser la méthode fit pour passer les données et la cible. Une fois l’entraînement fait, ce qui peut prendre plus ou moins de temps selon votre machine, nous pouvons trouver les meilleurs paramètres trouvés. Il nous faut accéder à la propriété best_params_ :

On voit ici que le modèle qui a le mieux fonctionné est celui avec peu d’arbres, mais très profond, et où chaque arbre voit une faible portion des données. Si on veut un détail des résultats, on peut regarder le cv_results_. Il contient toutes les informations sur les résultats des scores de test sur chaque split, sur les paramètres testés et leurs valeurs, etc…
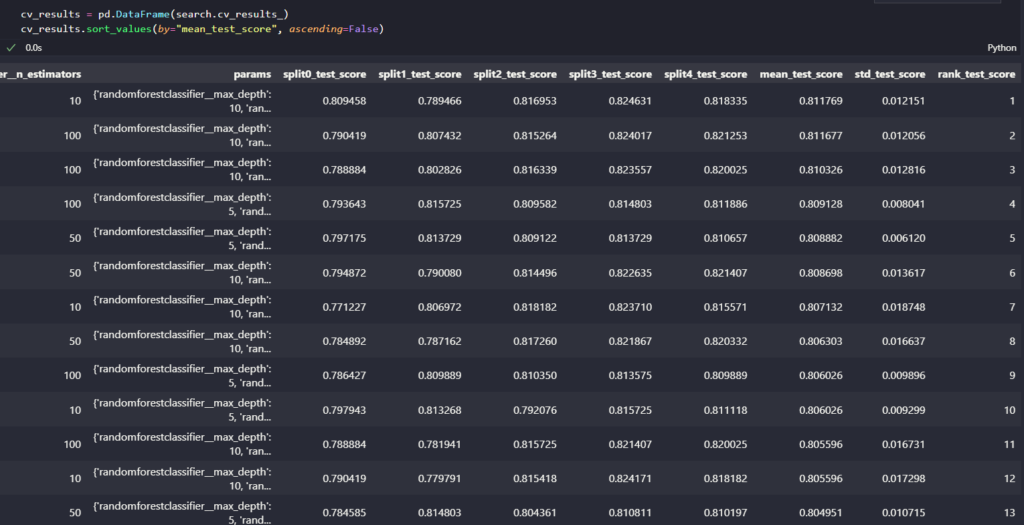
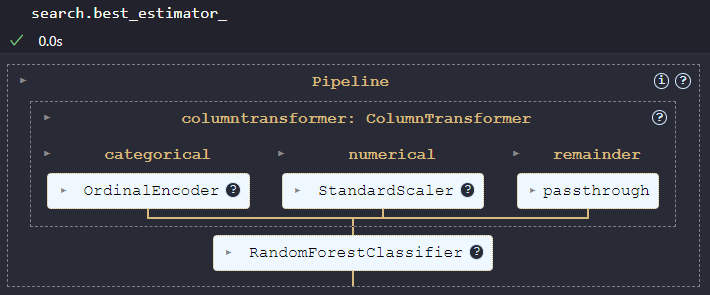
Enfin, si on veut récupérer le meilleur modèle, on peut le retrouver dans la propriété best_estimator_
Recherche aléatoire
La recherche aléatoire est un type de recherche où, comme pour la recherche par grille, nous allons limiter les paramètres et leurs valeurs. Seulement, là où la recherche par grille va tester toutes les combinaisons, la recherche aléatoire ne va en sélectionner qu’un nombre précis, que l’on a déterminé à l’avance. Et donc, on va pouvoir en mettre beaucoup pour avoir une plus grande diversité de valeurs, sans augmenter le nombre de modèles à tester.
Pour faire cette recherche avec scikit-learn, nous allons utiliser la classe sklearn.model_selection.RandomizedSearchCV. Comme sa soeur pour la recherche par grille, il va falloir définir une distribution des paramètres. Mais en plus, nous allons devoir déterminer à l’avance le nombre de modèles que nous voulons tester.
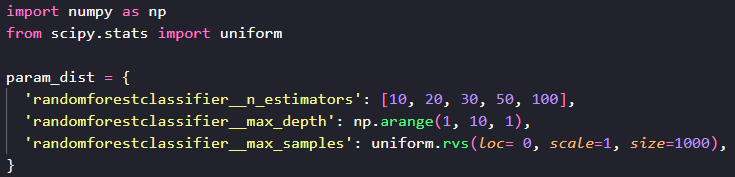
Ici, on peut utiliser des fonctions qui vont nous générer.
une grande quantité de nombres, comme np.arange de numpy qui va nous donner des valeurs ici de 1 à 10, ou encore la fonction uniform.rvs de scipy, qui va nous donner 1000 valeurs aléatoires entre 0 et 1 en suivant une distribution uniforme.
On aurait pu utiliser des listes simples, mais numpy et scipy sont des librairies intéressantes et je souhaitais vous montrer comment on peut les utiliser.
Ensuite, comme pour la recherche par grille, on passe le modèle, la distribution des paramètres, une métrique et le nombre de validations, et le modèle est bon à entraîner.

Ce paramètre n_iter sert à définir le nombre de modèles que l’on souhaite tester. Ici, nous en testons 100, ce qui a pris presque 4 minutes sur ma machine. Vous pouvez le revoir à la baisse si vous le souhaitez. Et de la même manière, on peut voir les meilleurs paramètres avec la propriété best_params_.

Évidemment, le résultat que vous aurez obtenu pourra être différent du mien, à cause de l’aspect aléatoire de la recherche. On voit aussi que le résultat obtenu est très proche de celui obtenu par la recherche par grille.
De la même manière, vous pourrez voir le détail des résultats dans la propriété cv_results_ et le meilleur modèle dans best_estimator_.
Conclusion
Vous savez maintenant optimiser et rechercher les meilleurs paramètres pour un modèle donné et effectuer une recherche hyperparamétrique ! Scikit-learn fournit encore d’autres manières de faire des recherches, selon d’autres heuristiques. Vous pouvez explorer la documentation pour cela.
Une des prochaines étapes que l’on pourrait envisager, serait de tester différents types de modèles pour un problème donné. Mais vous avez tous les outils nécessaires pour réaliser un tel projet avec scikit-learn.