
LangServe est une bibliothèque open-source développée pour simplifier considérablement le déploiement et la mise en production d’applications construites avec le framework LangChain. Son objectif principal est de permettre aux développeurs d’exposer rapidement et facilement leurs agents, chaînes et modèles LangChain sous forme d’API REST, rendant ainsi leur utilisation et leur intégration dans d’autres systèmes beaucoup plus aisées.
Basée sur le framework web Python FastAPI, reconnu pour ses performances et sa facilité d’utilisation, LangServe offre de nombreuses fonctionnalités clés pour accélérer la mise en production. Elle génère automatiquement une documentation OpenAPI complète et des schémas d’input/output pour chaque endpoint, permettant une compréhension et une utilisation rapide de l’API par les développeurs et les clients.
En plus de la génération d’API, LangServe inclut également un playground interactif très pratique pour tester et débugger les différents endpoints et chaînes, ainsi que des fonctionnalités de partage de configurations via des liens uniques. La bibliothèque fournit aussi un client Python pour appeler facilement les API déployées depuis d’autres applications.
Que vous soyez un data scientist cherchant à rendre ses modèles accessibles ou un développeur souhaitant intégrer des capacités de traitement du langage naturel dans ses applications, LangServe vous fera gagner un temps précieux en vous permettant de passer en un clin d’œil de l’expérimentation avec LangChain au déploiement en production dans le cloud (AWS, Azure, GCP, etc).
Dans cet article, nous verrons comment prendre en main LangServe pour déployer vos premiers endpoints, comment utiliser le client et le playground, et surtout comment mettre en production vos applications LangChain en quelques lignes de code sur les principaux cloud providers du marché.
Prérequis
Avant de vous lancer dans l’utilisation de LangServe, assurez-vous de disposer d’un environnement de développement Python fonctionnel sur votre machine. LangServe nécessite une version de Python 3.7 ou supérieure. Vous pouvez vérifier votre version de Python en exécutant la commande python --version dans votre terminal.
Le gestionnaire de paquets pip est également requis pour installer facilement LangServe et ses dépendances. Pip est généralement installé par défaut avec les versions récentes de Python. Pour vous en assurer, exécutez pip --version. Si pip n’est pas présent, référez-vous à la documentation officielle Python pour les instructions d’installation spécifiques à votre système d’exploitation.
Une connaissance de base du framework LangChain est fortement recommandée pour tirer pleinement parti de LangServe. Vous devriez être à l’aise avec les concepts clés tels que les agents, les chaînes, les modèles de langage et les prompts. Si vous débutez avec LangChain, il est conseillé de vous familiariser avec la documentation officielle et de parcourir quelques exemples avant de passer à LangServe.
De même, une compréhension des principes de base de FastAPI, le framework web sur lequel s’appuie LangServe, sera utile pour personnaliser et déboguer vos applications si nécessaire. FastAPI étant un framework très populaire et bien documenté, vous trouverez facilement de nombreuses ressources en ligne pour vous aider à prendre en main ses concepts fondamentaux, tels que le routing, les dépendances et la gestion des requêtes et des réponses.
Enfin, bien que cela ne soit pas strictement nécessaire pour commencer, avoir des notions sur les API REST, les schémas JSON et la documentation OpenAPI vous permettra de comprendre plus en profondeur le fonctionnement interne de LangServe et d’exploiter au mieux ses capacités de génération automatique.
En résumé, assurez-vous d’avoir :
- Python 3.7+ et pip installés
- Des connaissances de base de LangChain (agents, chaînes, modèles)
- Des notions de FastAPI (routing, dépendances, requêtes/réponses)
- Optionnel : une compréhension des API REST, JSON et OpenAPI
Une fois ces prérequis validés, vous serez prêt à installer LangServe et à créer votre première application !
Installation de LangServe
L’installation de LangServe s’effectue très simplement à l’aide du gestionnaire de paquets pip. Avant de procéder à l’installation, il est recommandé de créer et d’activer un nouvel environnement virtuel Python, afin d’éviter tout conflit avec les paquets systèmes ou d’autres projets. Vous pouvez utiliser venv, conda ou tout autre outil de gestion d’environnements virtuels de votre choix.
Une fois votre environnement virtuel activé, exécutez la commande suivante dans votre terminal pour installer LangServe avec toutes ses dépendances :
pip install "langserve[all]"Cette commande installera à la fois les composants serveur et client de LangServe, ainsi que les dépendances nécessaires telles que FastAPI, Uvicorn (un serveur ASGI rapide) et Pydantic (pour la validation des données).
Pip téléchargera et installera tous les paquets requis dans votre environnement virtuel. Une fois l’installation terminée, vous pourrez importer et utiliser LangServe dans votre code Python.
Il est important de noter que LangServe nécessite également une version récente du framework LangChain pour fonctionner correctement. Si vous n’avez pas encore installé LangChain, pip s’en chargera automatiquement lors de l’installation de LangServe. Cependant, si vous disposez déjà d’une installation de LangChain, assurez-vous qu’elle est à jour pour garantir une compatibilité optimale avec LangServe.
Maintenant que LangServe est installé dans votre environnement Python, vous êtes prêt à créer votre première application ! Dans la section suivante, nous verrons comment mettre en place un serveur FastAPI avec LangServe pour exposer des modèles de langage sous forme d’API.Première application LangServe
Pour découvrir le fonctionnement de base de LangServe, nous allons créer une application simple qui expose deux modèles de chat, l’un utilisant l’API d’OpenAI et l’autre celle d’Anthropic. Cette application permettra également d’invoquer une chaîne combinant un template de prompt et le modèle d’Anthropic pour générer des blagues sur un sujet donné.
Voici le code complet de notre application :
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
version="1.0",
description="Un serveur API simple utilisant les interfaces Runnable de LangChain",
)
# Expose le modèle ChatOpenAI sous le chemin /openai
add_routes(
app,
ChatOpenAI(),
path="/openai",
)
# Expose le modèle ChatAnthropic sous le chemin /anthropic
add_routes(
app,
ChatAnthropic(),
path="/anthropic",
)
model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("Raconte-moi une blague à propos de {topic}")
# Expose la chaîne prompt | model sous le chemin /blague
add_routes(
app,
prompt | model,
path="/blague",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)Décortiquons ce code étape par étape :
- Nous commençons par importer les dépendances nécessaires :
FastAPIpour créer notre application web,ChatPromptTemplatepour définir notre template de prompt,ChatAnthropicetChatOpenAIpour les modèles de chat, et enfinadd_routesde LangServe pour exposer nos composants en tant qu’API. - Nous créons une instance de l’application FastAPI, en spécifiant un titre, une version et une description. Ces informations seront utilisées pour générer la documentation OpenAPI de notre API.
- Nous utilisons la fonction
add_routesde LangServe pour exposer notre premier modèle, une instance deChatOpenAI, sous le chemin/openai. Cela générera automatiquement tous les endpoints nécessaires pour interagir avec le modèle (invoke, astream, batch, etc.). - De la même manière, nous exposons une instance de
ChatAnthropicsous le chemin/anthropic. - Nous créons ensuite une chaîne combinant un template de prompt (demandant une blague sur un sujet donné) et le modèle d’Anthropic, en utilisant l’opérateur
|de LangChain. Cette chaîne est exposée sous le chemin/blaguegrâce àadd_routes. - Enfin, nous ajoutons une condition
if __name__ == "__main__"pour lancer notre serveur avec Uvicorn lorsque le script est exécuté directement. Le serveur écoutera surlocalhostau port 8000.
Pour lancer l’application, exécutez simplement le script Python. Uvicorn démarrera alors le serveur, et vous pourrez accéder à votre API à l’adresse http://localhost:8000.
Grâce à la magie de LangServe et de FastAPI, une documentation OpenAPI complète est automatiquement générée pour votre API. Vous pouvez y accéder en naviguant vers http://localhost:8000/docs dans votre navigateur web. Cette documentation interactive vous permet de visualiser tous les endpoints disponibles, leurs schémas d’entrée et de sortie, et même de les tester directement depuis l’interface web.
Vous pouvez également accéder au playground de LangServe pour chaque composant en ajoutant /playground à son chemin (par exemple, http://localhost:8000/openai/playground). Le playground fournit une interface utilisateur conviviale pour tester les différentes fonctionnalités de votre API.
Et voilà ! Avec seulement quelques lignes de code, vous avez créé une API complète capable d’exécuter des modèles de chat et des chaînes personnalisées. LangServe s’occupe de tous les détails techniques, vous permettant de vous concentrer sur la logique métier de votre application.
Dans la section suivante, nous verrons comment utiliser le client Python fourni par LangServe pour interagir avec notre nouvelle API.
Client Python pour appeler l’API
Maintenant que notre API est opérationnelle, voyons comment interagir avec elle en utilisant le SDK client Python fourni par LangServe. Ce SDK permet d’appeler facilement les différents endpoints de l’API comme si les composants étaient exécutés localement, tout en gérant de manière transparente les communications réseau et la sérialisation des données.
Voici un exemple de code client utilisant le SDK LangServe pour appeler notre API :
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable
# Création d'instances de RemoteRunnable pour chaque modèle
openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/blague/")
# Appel de la chaîne de blagues de manière synchrone
response = joke_chain.invoke({"topic": "les chats"})
print(response)
# Définition d'un prompt sous forme de messages
prompt = [
SystemMessage(content="Agis comme un assistant nommé Claude."),
HumanMessage(content="Bonjour Claude ! Comment vas-tu ?"),
]
# Streaming de la réponse du modèle Anthropic de manière asynchrone
async for token in anthropic.astream(prompt):
print(token, end="", flush=True)
# Définition d'un nouveau prompt avec un template
prompt = ChatPromptTemplate.from_messages([
("system", "Tu es un assistant qui écrit de longues histoires sur un sujet donné."),
])
# Construction d'une chaîne personnalisée combinant les deux modèles
chain = prompt | RunnableMap({
"openai": openai,
"anthropic": anthropic,
})
# Appel de la chaîne personnalisée en mode batch
responses = chain.batch([{"topic": "les perroquets"}, {"topic": "les chats"}])
print(responses)
Le SDK expose une classe RemoteRunnable qui encapsule la logique d’appel aux différents endpoints de l’API. Pour chaque composant que nous souhaitons utiliser, nous créons une instance de RemoteRunnable en spécifiant son URL.
Nous pouvons alors appeler les méthodes invoke et astream sur ces instances pour exécuter les composants de manière synchrone ou asynchrone, comme s’ils étaient de simples objets Python.
La méthode invoke envoie une requête unique à l’endpoint /invoke de l’API et renvoie la réponse complète. C’est le mode d’appel le plus simple, idéal pour les tâches ne nécessitant pas de streaming.
La méthode astream, quant à elle, envoie une requête à l’endpoint /astream et renvoie un générateur asynchrone qui yield les tokens de la réponse au fur et à mesure de leur génération par le serveur. Ce mode est parfait pour obtenir des résultats en temps réel et afficher une réponse progressive à l’utilisateur.
Le SDK permet également de construire facilement des chaînes personnalisées en combinant plusieurs composants distants à l’aide de l’opérateur |, de la même manière qu’avec des composants locaux. On peut ainsi tirer parti de la flexibilité de LangChain pour créer des pipelines de traitement complexes qui s’exécutent de manière transparente via des appels API.
En résumé, le SDK LangServe simplifie grandement l’utilisation d’APIs LangChain depuis des applications Python. Grâce à une interface intuitive calquée sur celles des composants locaux, il devient un jeu d’enfant d’intégrer des modèles et des chaînes distantes dans votre code. Le SDK gère pour vous tous les aspects bas niveau comme la sérialisation JSON et les requêtes HTTP, vous permettant de vous concentrer sur la logique de votre application.
Dans la prochaine section, nous explorerons d’autres moyens d’appeler notre API LangServe, en utilisant divers langages et outils tels que TypeScript, Python avec requests et curl en ligne de commande.
Autres clients
En plus du SDK Python officiel, LangServe permet d’interagir avec les APIs déployées depuis une multitude d’autres langages et outils. Que vous préfériez travailler avec TypeScript, Python sans dépendances supplémentaires ou même directement en ligne de commande avec curl, LangServe offre une grande flexibilité pour s’adapter à votre environnement de développement.
Client TypeScript avec LangChain.js
Pour les développeurs travaillant dans l’écosystème JavaScript/TypeScript, LangChain.js propose un client compatible avec LangServe à partir de sa version 0.0.166. Ce client vous permet d’appeler les APIs LangServe de manière intuitive et fortement typée.
Voici un exemple d’utilisation du client TypeScript pour invoquer la chaîne de blagues que nous avons déployée précédemment :
import { RemoteRunnable } from "@langchain/core/runnables/remote";
const chain = new RemoteRunnable({
url: "http://localhost:8000/blague/", // URL de l'API LangServe
});
const result = await chain.invoke({ topic: "les chats" });
console.log(result); // Affiche le résultat de l'APILe client expose une classe RemoteRunnable similaire à celle du SDK Python, rendant l’utilisation de LangServe cohérente et familière quelle que soit la plateforme.
Appels API en Python avec requests
Si vous souhaitez interagir avec une API LangServe depuis un script Python sans installer de dépendances supplémentaires, vous pouvez utiliser directement la bibliothèque standard requests. Cette approche est un peu plus verbeuse que l’utilisation du SDK officiel, mais offre une grande flexibilité et peut être utile dans certains scénarios.
Voici comment appeler l’endpoint /blague/invoke en utilisant requests :
import requests
response = requests.post(
"http://localhost:8000/blague/invoke", # URL de l'endpoint d'invocation
json={"input": {"topic": "les chats"}} # Paramètres d'entrée au format JSON
)
result = response.json() # Décode la réponse JSON
print(result) # Affiche le résultatIl suffit de spécifier l’URL complète de l’endpoint, de fournir les paramètres d’entrée au format JSON dans le corps de la requête, et de récupérer le résultat en décodant la réponse JSON.
Utilisation de curl en ligne de commande
Enfin, pour les amateurs de ligne de commande ou pour les situations où l’installation d’un SDK n’est pas pratique, LangServe peut être utilisé directement avec l’outil curl. Cette approche est idéale pour tester rapidement une API ou pour l’intégrer dans des scripts shell.
Voici un exemple d’appel à l’endpoint /blague/invoke avec curl :
curl --location --request POST 'http://localhost:8000/blague/invoke' \
--header 'Content-Type: application/json' \
--data-raw '{
"input": {
"topic": "les chats"
}
}'On spécifie la méthode HTTP (POST), l’URL de l’endpoint, le type de contenu (application/json) et les paramètres d’entrée au format JSON. curl se charge d’envoyer la requête et affiche la réponse directement dans le terminal.
En résumé, LangServe se distingue par son excellente interopérabilité et sa facilité d’intégration. Grâce à une API REST standard et bien documentée, il est possible d’interagir avec les endpoints LangServe depuis pratiquement n’importe quel langage ou outil capable d’envoyer des requêtes HTTP. Que vous soyez un adepte de TypeScript, de Python ou même de curl, LangServe s’adapte à votre environnement et à vos préférences, vous permettant de tirer parti de ses fonctionnalités avancées en toute simplicité.
Playground LangServe
Le playground est une fonctionnalité très pratique proposée par LangServe pour tester et déboguer facilement les différents endpoints et chaînes déployés. Il s’agit d’une interface web interactive, accessible directement depuis l’API, qui permet d’exécuter des requêtes sur les composants sans avoir à écrire de code.
Pour accéder au playground d’un composant, il suffit d’ajouter /playground à la fin de son URL de base. Par exemple, si nous avons déployé une chaîne sous le chemin /ma_chaine, son playground sera accessible à l’adresse http://mon-serveur.com/ma_chaine/playground.
Le playground propose une interface utilisateur intuitive, divisée en plusieurs sections :
- Saisie des paramètres d’entrée : Un éditeur JSON permet de saisir les paramètres d’entrée attendus par l’endpoint sélectionné. Le schéma JSON du composant est affiché à titre indicatif pour connaître le format attendu.
- Exécution de la requête : Un bouton « Exécuter » permet de lancer la requête vers l’endpoint sélectionné avec les paramètres saisis.
- Affichage du résultat : La réponse renvoyée par l’API est affichée dans un volet dédié, avec coloration syntaxique pour faciliter la lecture. En cas d’erreur (paramètres manquants, format invalide, etc.), le message d’erreur est affiché pour aider au débogage.
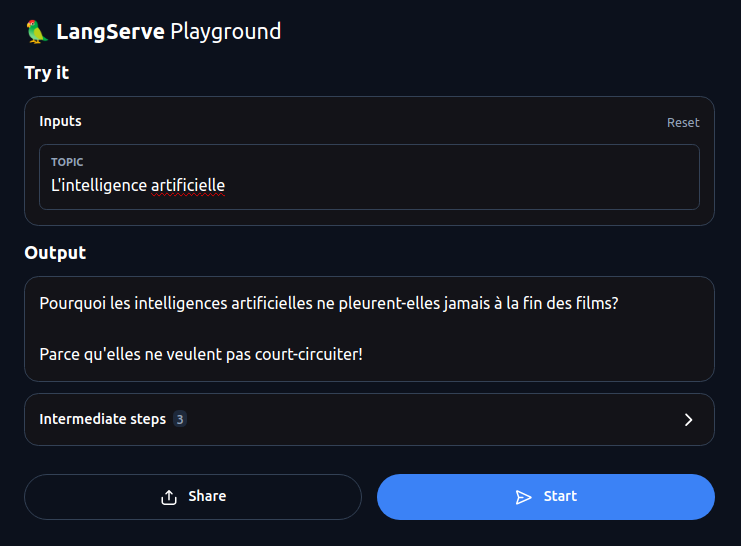
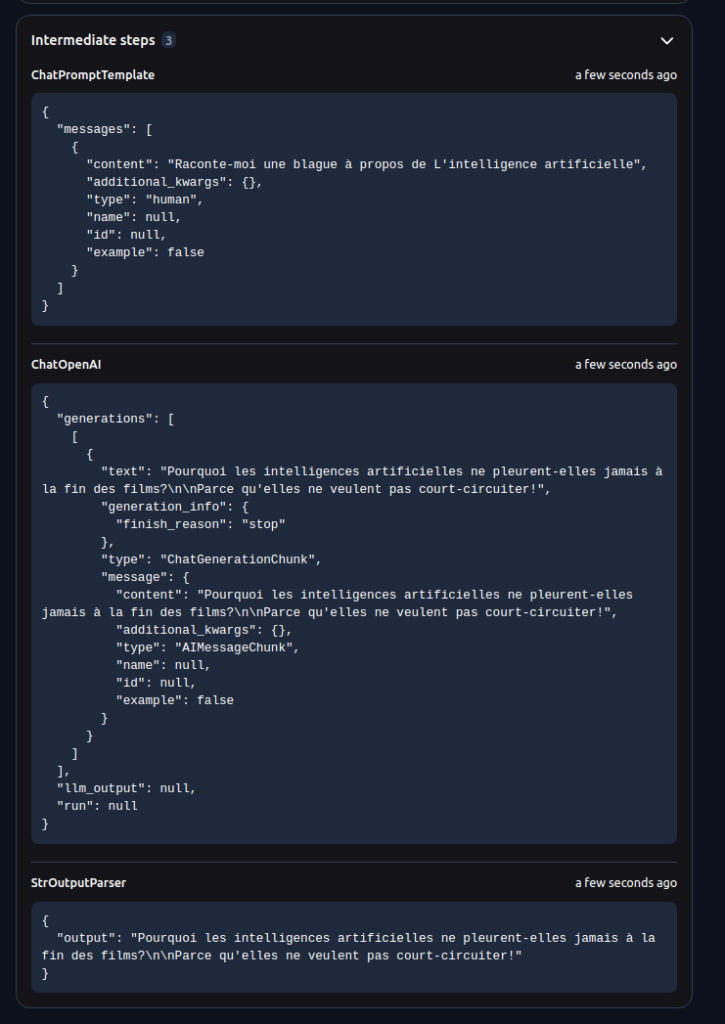
Le playground supporte également le test des endpoints en streaming (comme /astream). Dans ce cas, la réponse est affichée en temps réel, au fur et à mesure de la réception des données depuis le serveur.
L’un des principaux avantages du playground est qu’il est entièrement auto-documenté. Chaque endpoint est décrit de manière détaillée, avec des explications sur son comportement, ses paramètres d’entrée et son format de sortie. Les schémas JSON des types d’entrée et de sortie sont également affichés, servant de référence pour construire des requêtes valides.
De plus, le playground est directement lié à la documentation OpenAPI de l’API. Il est possible de naviguer de manière fluide entre les deux interfaces pour consulter les spécifications détaillées de chaque endpoint tout en les testant de manière interactive.
Le playground de LangServe offre également des fonctionnalités avancées pour certains types de composants. Par exemple, pour les chaînes de conversation (chat), il propose une interface spécialisée permettant de visualiser l’historique des échanges et de saisir de nouveaux messages de manière naturelle.
En résumé, le playground est un outil essentiel proposé par LangServe pour faciliter le test et le débogage des APIs déployées. Grâce à son interface web intuitive, auto-documentée et liée à la spécification OpenAPI, il permet aux développeurs d’explorer et de valider le comportement des composants de manière interactive, sans avoir à écrire de code. Le support des requêtes en streaming et les interfaces spécialisées pour certains types de composants en font un véritable atout pour la productivité et la qualité des APIs créées avec LangServe.
Partage et liens
Une fois votre API LangServe déployée et testée, vous souhaiterez probablement la partager avec d’autres développeurs ou l’intégrer dans d’autres applications. LangServe propose des fonctionnalités avancées de partage et de génération de liens pour faciliter ces tâches.
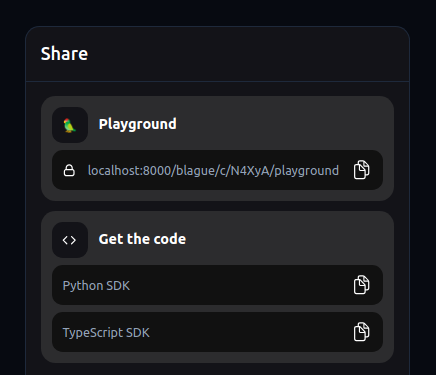
Chaque composant déployé via LangServe est associé à un lien unique, qui peut être partagé pour permettre à d’autres personnes d’accéder directement à son playground. Ce lien a la forme suivante : https://votre-api.com/chemin/du/composant/playground.
Il suffit de copier-coller ce lien et de l’envoyer aux développeurs concernés. En l’ouvrant dans leur navigateur, ils accéderont à une interface interactive leur permettant de tester le composant avec différentes entrées, de visualiser les résultats et de consulter la documentation associée. C’est un excellent moyen de présenter les fonctionnalités de votre API et de permettre à d’autres de l’essayer sans avoir à configurer un environnement de développement.
De plus, pour les composants paramétrables (configurable runnables), le playground de LangServe offre la possibilité de générer des liens spécifiques à une configuration donnée. Imaginons par exemple que vous avez déployé une chaîne de requêtage (retrieval chain) dans laquelle l’utilisateur peut sélectionner la base de connaissances à interroger via un paramètre nommé knowledge_base.
Depuis le playground, vous pouvez choisir une base de connaissances spécifique, disons knowledge_base_42, remplir éventuellement d’autres paramètres, puis cliquer sur le bouton « Copier le lien » qui apparaît. Vous obtiendrez alors un lien de la forme https://votre-api.com/chemin/du/composant/playground?params=... qui encode la configuration choisie.
En partageant ce lien, vous permettez à quiconque de tester votre composant avec la configuration pré-remplie, sans avoir à sélectionner manuellement la base de connaissances ou à ajuster d’autres paramètres. C’est particulièrement utile pour présenter un cas d’usage précis, partager un résultat intéressant ou faciliter le débogage d’une configuration particulière.
Il est important de noter que ces liens donnent un accès en lecture seule à votre API. Les personnes qui les utilisent peuvent exécuter le composant avec les paramètres fournis, mais ne peuvent pas modifier le code ou la configuration sous-jacente. Les liens de playground générés sont donc un moyen sûr et pratique de partager et de promouvoir votre travail.
En résumé, les fonctionnalités de partage et de génération de liens offertes par LangServe sont un atout précieux pour faciliter la collaboration et la démonstration autour de vos APIs. En quelques clics, vous pouvez permettre à d’autres développeurs de tester vos composants de manière interactive, avec une configuration personnalisée, tout en préservant la sécurité de votre déploiement. C’est une excellente façon de mettre en valeur vos réalisations, de recueillir des retours et de susciter l’intérêt pour vos APIs basées sur LangChain.
Déploiement en production
Le déploiement en production est une étape cruciale dans le cycle de vie d’une application, et les APIs développées avec LangServe ne font pas exception. Il s’agit de rendre votre application accessible aux utilisateurs finaux de manière fiable, performante et sécurisée.
LangServe a été conçu pour faciliter le déploiement sur les principaux fournisseurs de cloud, en tirant parti de technologies éprouvées comme les conteneurs Docker. Voici un aperçu des options de déploiement recommandées pour différentes plateformes.
Déploiement sur AWS
Amazon Web Services (AWS) est l’un des leaders du marché du cloud computing, offrant une large gamme de services pour héberger et orchestrer des applications. Pour déployer une API LangServe sur AWS, nous recommandons d’utiliser AWS Copilot, un outil en ligne de commande qui simplifie la gestion des applications conteneurisées.
Voici les étapes générales pour déployer avec AWS Copilot :
- Installez la CLI AWS Copilot en suivant la documentation officielle.
- Initialisez un nouvel environnement Copilot pour votre application :
copilot init --app mon-app --name mon-service --type 'Load Balanced Web Service' --dockerfile './Dockerfile' --deployCette commande crée les fichiers de configuration nécessaires, construit l’image Docker de votre application et la déploie sur un cluster ECS (Elastic Container Service).
- AWS Copilot expose automatiquement votre API sur un load balancer, qui distribue le trafic vers les instances de votre conteneur. Vous pouvez récupérer l’URL publique de votre API avec la commande suivante :
copilot svc show --name mon-service --urlAWS Copilot offre de nombreuses autres fonctionnalités, comme le déploiement canary, la gestion des variables d’environnement, l’auto-scaling, etc. Référez-vous à la documentation officielle pour en savoir plus.
Déploiement sur Azure
Microsoft Azure est une autre plateforme cloud populaire, qui propose des services de calcul, de stockage et de mise en réseau. Pour déployer une API LangServe sur Azure, nous recommandons d’utiliser Azure Container Apps, un service entièrement géré pour exécuter des applications conteneurisées.
Voici comment déployer avec Azure Container Apps :
- Installez la CLI Azure en suivant la documentation officielle.
- Connectez-vous à votre compte Azure avec la commande suivante :
az login- Créez un groupe de ressources pour votre application :
az group create --name mon-groupe-ressources --location eastus- Créez un environnement Azure Container Apps :
az containerapp env create --name mon-environnement --resource-group mon-groupe-ressources --location eastus- Déployez votre application en spécifiant le Dockerfile :
az containerapp create --name mon-app --resource-group mon-groupe-ressources --environment mon-environnement --image mon-registry.azurecr.io/mon-image:tag --target-port 8000 --ingress 'external'Cette commande construit l’image Docker de votre application, la pousse sur un registre de conteneurs (Azure Container Registry) et la déploie sur Azure Container Apps. Votre API est alors accessible via une URL publique.
Pour en savoir plus sur Azure Container Apps, référez-vous à la documentation officielle.
Déploiement sur Google Cloud Platform
Google Cloud Platform (GCP) est la plateforme cloud de Google, qui propose une suite complète de services pour déployer et gérer des applications. Pour déployer une API LangServe sur GCP, nous recommandons d’utiliser Cloud Run, un service de calcul serverless entièrement géré pour les applications conteneurisées.
Voici les étapes pour déployer avec Cloud Run :
- Installez la CLI Google Cloud en suivant la documentation officielle.
- Initialisez le SDK Google Cloud avec la commande suivante :
gcloud initSuivez les instructions pour vous connecter à votre compte GCP et sélectionner un projet.
- Construisez et poussez l’image Docker de votre application vers Google Container Registry :
gcloud builds submit --tag gcr.io/mon-projet/mon-app- Déployez votre application sur Cloud Run :
gcloud run deploy mon-app --image gcr.io/mon-projet/mon-app --platform managed --allow-unauthenticated --region us-central1 --port 8000Cette commande déploie votre image Docker sur une instance de Cloud Run et rend votre API accessible via une URL publique.
Cloud Run offre de nombreuses fonctionnalités avancées, comme la mise à l’échelle automatique, les déploiements progressifs, la gestion des secrets, etc. Référez-vous à la documentation officielle pour en savoir plus.
Conclusion
Au terme de cet article, nous avons pu mesurer à quel point LangServe constitue un outil précieux pour industrialiser et mettre en production des applications construites avec le framework LangChain. En simplifiant considérablement le déploiement d’agents, de chaînes et de modèles sous forme d’APIs REST, LangServe permet aux développeurs de se concentrer sur la logique métier de leurs applications tout en bénéficiant de capacités avancées en termes de documentation, de test et de partage.
La génération automatique d’une documentation OpenAPI exhaustive et de schémas JSON pour chaque endpoint déployé est un atout majeur pour favoriser l’adoption et l’intégration des APIs créées avec LangServe. Grâce à une documentation toujours à jour et facilement accessible, les développeurs peuvent rapidement comprendre et utiliser ces APIs dans leurs propres projets.
Le playground interactif proposé par LangServe est un autre point fort de cette bibliothèque. En permettant de tester et de déboguer les différents composants de manière visuelle et interactive, directement depuis l’interface web de l’API, il facilite grandement la prise en main et l’expérimentation. Les fonctionnalités de partage de configurations via des liens uniques sont également très appréciables pour collaborer efficacement autour des APIs.
Sur le plan de la mise en production, LangServe s’intègre parfaitement avec les principaux fournisseurs de cloud computing comme Amazon Web Services, Microsoft Azure ou Google Cloud Platform. Le déploiement sous forme de conteneurs Docker, orchestré par des outils comme AWS Copilot, Azure Container Apps ou Google Cloud Run, apporte un haut niveau de flexibilité et de portabilité. Les APIs ainsi déployées bénéficient de toute la puissance et de la fiabilité des infrastructures cloud, tout en minimisant les efforts d’administration système.
En conclusion, LangServe apparaît comme la solution idéale pour industrialiser et valoriser les applications basées sur LangChain. Grâce à ses fonctionnalités avancées de génération d’API, de documentation, de test et de déploiement, cette bibliothèque ouvre de nouvelles perspectives pour la démocratisation des technologies de traitement du langage naturel. Que vous soyez data scientist, développeur ou architecte, LangServe vous accompagnera efficacement dans la mise en production de vos modèles et agents conversationnels, vous permettant ainsi de créer de la valeur rapidement et sereinement.
Pour aller plus loin avec LangServe, n’hésitez pas à consulter les ressources suivantes :
- La documentation officielle de LangServe
- Le dépôt d’exemples proposant de nombreux cas d’usage concrets de LangChain
- Le blog de LangChain pour découvrir les dernières avancées et bonnes pratiques autour de la bibliothèque
Nul doute que LangServe deviendra rapidement un outil incontournable pour toute personne souhaitant construire des applications de traitement du langage à l’état de l’art et les mettre en production en toute simplicité. Son intégration harmonieuse avec LangChain et son orientation résolument tournée vers le déploiement en font un choix stratégique pour les projets d’envergure.

