L’IA est sur toutes les lèvres. Mais derrière ce mot, que met-on vraiment ? Depuis que je me forme au développement d’IA, je découvre qu’il y a plusieurs réalités : le machine learning traditionnel, les modèles de deep learning, les IA génératives… et surtout, un fossé considérable entre ce qu’on apprend à faire, et ce que les entreprises utilisent réellement.
Pourtant, malgré ces différences, un élément reste central : les données. Quelle que soit la méthode utilisée – qu’il s’agisse d’apprentissage automatique, de réseaux neuronaux ou d’IA générative – elles reposent toutes sur l’exploitation de vastes volumes de données. Ce sont elles qui façonnent les modèles, affinent leurs prédictions et leur permettent de générer du contenu pertinent. Sans données, pas d’IA. Et c’est justement la qualité, la diversité et la gestion de ces données qui conditionnent la pertinence et l’efficacité des solutions mises en place en entreprise.
En tant qu’apprentie développeuse IA, je suis confrontée à la fois aux projets pédagogiques (où l’on entraîne beaucoup de modèles) et aux réalités métiers (où l’on consomme surtout de l’IA via API). « Faire de l’IA » ne veut pas dire la même chose selon les contextes. Entre les modèles que nous entraînons à la main en formation, et les solutions prêtes à l’emploi que j’observe en entreprise, il y a tout un monde. Et c’est justement dans cet écart que se situent les vrais enjeux d’intégration de l’IA aujourd’hui.
🔹Machine learning : les fondations invisibles de l’IA
Apprendre à entraîner un modèle, c’est comprendre ce qu’est vraiment une IA. On manipule des données, on les analyse pour qu’elles correspondent au besoin, on ajuste des paramètres, on fait du feature engineering… Chaque ajustement, chaque choix de feature influence directement la performance du modèle. Ce processus de réglage, bien qu’essentiel, est souvent aussi un jeu d’essais-erreurs où l’expérience et la connaissance du domaine font toute la différence. Bref, on crée une « intelligence » sur mesure.
Ce travail est lent, coûteux et fragile. Il faut du temps, des ressources, et une très bonne compréhension du domaine. En formation, j’ai entraîné des modèles pour prédire la gravité d’un accident de la route, ou encore le prix d’un bien immobilier. À chaque fois, il a fallu explorer les données, les analyser, les nettoyer lorsqu’elles sont inexploitables (valeurs manquantes, biaisées, etc.), concevoir des features pertinentes, choisir un algorithme, transformer les données si nécessaire, tester, évaluer avec les bonnes métriques, réajuster. C’est là qu’on comprend ce que signifie réellement « entraîner un modèle » : un savant mélange de rigueur statistique, d’itérations, et de ressources… qu’on n’a pas toujours.
Comprendre l’IA, c’est plonger dans le machine learning. Apprendre à développer une IA, c’est d’abord apprendre à manipuler des données. Beaucoup de données. Nettoyer, trier, enrichir, découper, transformer… ce qui prend environ 70% du temps de travail. Ce travail de fond, invisible pour l’utilisateur final, est pourtant indispensable.
C’est cette maîtrise du machine learning qui constitue le socle sur lequel reposent les modèles plus complexes : sans une bonne gestion des données et des bases solides, l’IA avancée ne pourrait exister.
Les défis de l’entraînement de modèles :
- Volume et complexité des données
- Ressources limitées
- Problèmes de qualité des données
- Choix techniques complexes
L’entraînement d’un modèle IA implique plusieurs défis majeurs. Le volume et la complexité des données jouent un rôle essentiel : restreindre le dataset accélère l’entraînement, mais peut nuire à la capacité du modèle à bien généraliser. Un GridSearchCV, par exemple, peut devenir très coûteux en temps si le dataset est trop volumineux.
Les ressources limitées constituent aussi un frein. Travailler sur un simple PC portable avec des calculs intensifs est souvent impraticable. Des alternatives comme le cloud computing ou l’optimisation GPU existent, mais leur coût peut limiter leur accessibilité aux petites structures ou aux indépendants.
La qualité des données est un facteur critique souvent sous-estimé. Outliers, valeurs manquantes, problèmes d’échelle et biais impactent directement les performances du modèle. Ce travail de nettoyage est chronophage, mais essentiel pour obtenir un modèle fiable.
Enfin, les choix techniques influencent fortement les résultats. RandomForest ou XGBoost ? Régression linéaire ou réseau de neurones ? Chaque approche a des implications sur la performance et l’interprétabilité du modèle, et nécessite une analyse fine avant d’être adoptée.
🔹Le machine learning traditionnel vs. le deep learning : deux mondes différents
Dans ma formation, j’ai d’abord appris les algorithmes classiques (régression, arbres de décision, SVM…) avant de plonger dans le deep learning. Et j’ai rapidement compris que ce sont deux approches fondamentalement différentes.
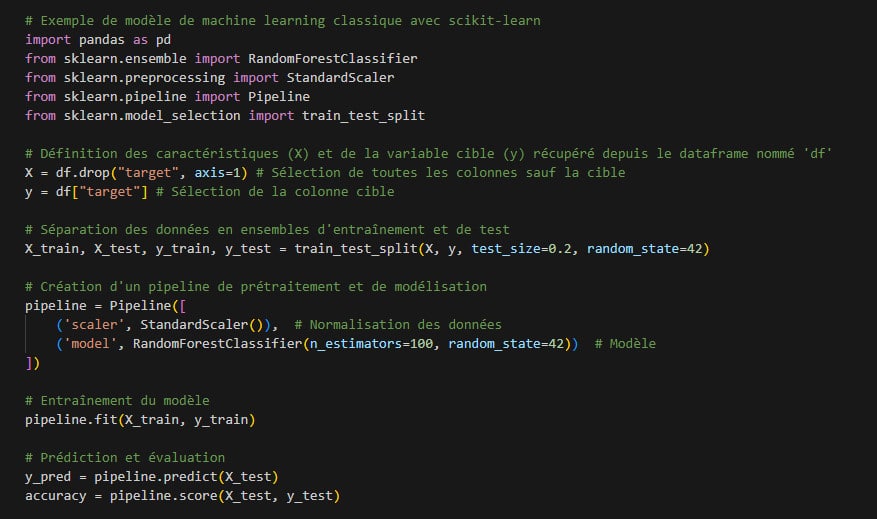
Pour mieux comprendre cette différence, voici deux approches typiques : un modèle de machine learning classique et un réseau de neurones en deep learning.
Exemple de modèle de machine learning :
Exemple de réseau de neurones :
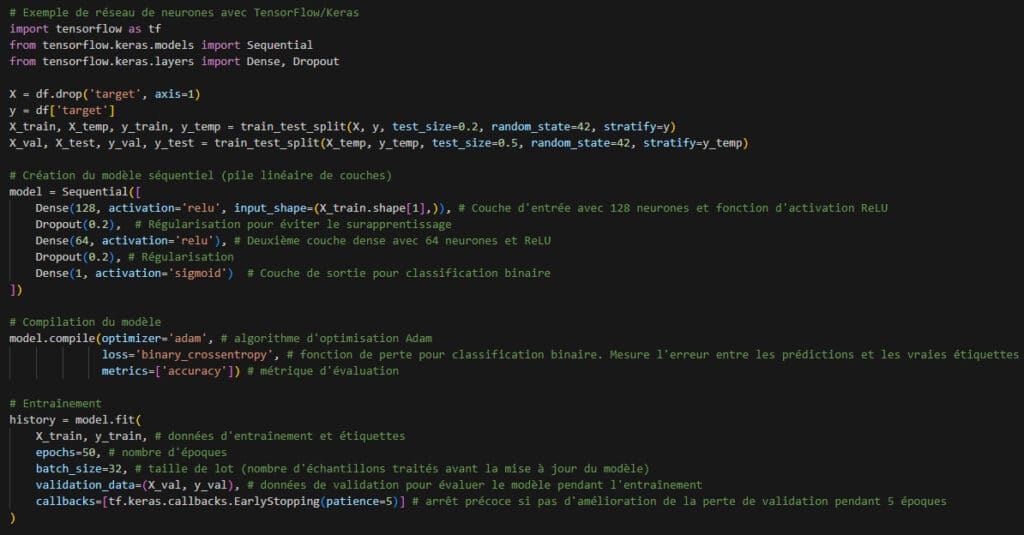
Le premier exemple utilise scikit-learn, idéal pour des problèmes classiques avec des datasets de taille raisonnable. Le second, avec TensorFlow, est typique du deep learning : plus de paramètres, plus de complexité, mais potentiellement plus de puissance pour des données non structurées ou très volumineuses.
Les modèles classiques sont souvent privilégiés pour leur interprétabilité, alors que les réseaux neuronaux offrent plus de puissance mais sont plus difficiles à expliquer. En plus de leur complexité, les réseaux de neurones nécessitent une puissance de calcul bien supérieure, ce qui explique leur préférence pour les environnements cloud ou les machines équipées de GPU.
🔹 IA pré-entraînée : l’option rapide, mais pas toujours maîtrisée
En entreprise, on n’entraîne pas toujours ses propres modèles. Dans beaucoup de cas, on fait appel à des IA via des API : ChatGPT, Claude, Gemini… Ce sont des « agents » capables de générer du texte, d’interagir avec les utilisateurs, de résumer des documents. C’est rapide à intégrer. Mais le défi devient alors : comment contrôler leur comportement ?
Les défis de l’utilisation d’IA pré-entraînées :
- Contrôle du comportement
- Manque de transparence
- Dépendance aux fournisseurs
- Personnalisation limitée
- Coûts d’intégration cachés
- Enjeu éthique et légal
- Enjeu environnemental
L’utilisation d’IA pré-entraînées pose plusieurs défis. Le contrôle du comportement est un enjeu majeur : ajuster les prompts et cadrer le contexte est indispensable pour obtenir des réponses cohérentes et éviter les dérives.
Le manque de transparence est aussi problématique. De nombreux modèles fonctionnent comme une boîte noire, rendant difficile la compréhension des décisions prises par l’algorithme.
La dépendance aux fournisseurs est un risque à anticiper : changement de tarification, nouvelles conditions d’utilisation ou arrêt du service peuvent impacter les opérations d’une entreprise.
Côté personnalisation, les modèles généralistes peuvent mal interpréter les spécificités d’un domaine ou employer un vocabulaire inadapté.
Les coûts d’intégration cachés sont souvent sous-estimés. Au-delà du coût par token, il faut prendre en compte la latence du service, les ajustements nécessaires pour garantir la qualité des réponses et les développements supplémentaires pour gérer les erreurs et les contraintes techniques.
Enfin, il y a un enjeu éthique et légal : que deviennent les données traitées ? Comment garantir leur confidentialité ? De plus en plus de régulations émergent pour superviser ces usages. Si le RGPD encadre la protection des données personnelles, le RIA (IA Act) vise à réguler l’usage des systèmes d’intelligence artificielle en fonction de leur niveau de risque. Il ne fixe pas encore un cadre strict pour toutes les IA, mais définit des catégories allant du risque minimal au risque inacceptable.
L’impact environnemental est également préoccupant. Les centres de données qui hébergent et entraînent ces modèles consomment des quantités massives d’énergie et d’eau, générant une empreinte carbone non négligeable. La chaleur dégagée par ces infrastructures nécessite des systèmes de refroidissement intensifs, accentuant encore leur impact écologique. Face à ces enjeux, certaines entreprises explorent des solutions comme la réutilisation de la chaleur fatale ou la capture du CO₂, mais ces initiatives restent marginales. À mesure que l’IA se démocratise, la question de sa durabilité devient un enjeu central.
Voici un exemple concret d’intégration d’une API d’IA générative dans une application Python :
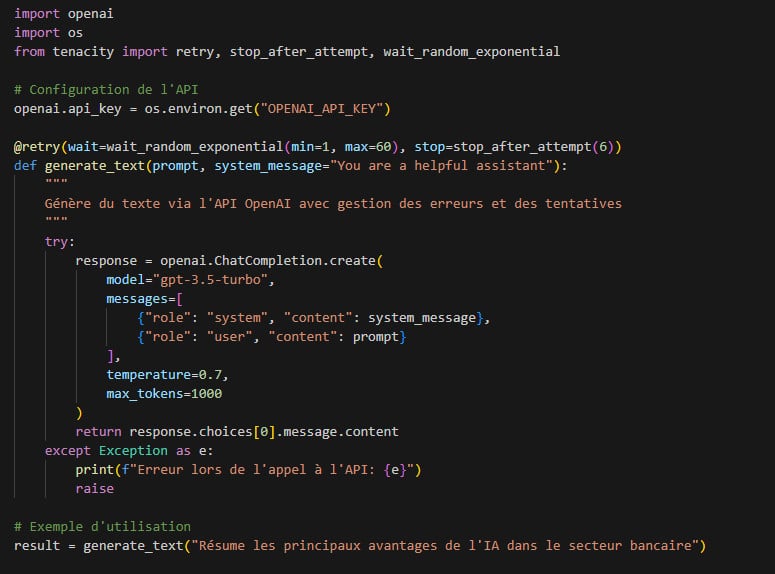
Ce code illustre plusieurs points importants :
- La gestion des erreurs et des retries, indispensable en production
- La séparation entre prompt utilisateur et message système
- Le réglage des paramètres comme la température qui influence la créativité de la réponse
🔹 Développer avec l’IA : entre micro-services, prompts et RAG
Aujourd’hui, on ne développe plus une IA. On développe autour d’elle. On crée une API, une interface, un micro-service qui va se connecter à un agent via une requête, on vectorise des documents, on construit des flux (LangChain, LangGraph, etc.). C’est une nouvelle forme de programmation. On « oriente » une intelligence existante vers une tâche précise.
Le rôle du développeur IA évolue : il ne s’agit plus tant d’entraîner des modèles que de les exploiter intelligemment dans des flux de travail existants. Désormais, maîtriser LangChain, les bases vectorielles et l’orchestration devient aussi important que connaître les algorithmes d’apprentissage.
Focus sur les concepts clés :
- LangChain et LangGraph
- Bases de données vectorielles et embeddings
- RAG (Retrieval Augmented Generation)
L’enjeu est moins scientifique que conceptionnel.
Les frameworks LangChain et LangGraph permettent d’orchestrer les interactions avec les LLM, d’enchaîner les actions et de construire des pipelines complexes. Ils sont essentiels pour structurer les réponses d’une IA tout en améliorant la contextualisation et la logique des interactions.
Les bases de données vectorielles et les embeddings sont des techniques avancées qui transforment le sens des mots et des phrases sous forme de vecteurs mathématiques, permettant de faire des recherches sémantiques et de retrouver l’information pertinente pour alimenter l’IA.
Enfin, le RAG (Retrieval Augmented Generation) améliore la fiabilité des réponses générées par l’IA en s’appuyant sur des bases de connaissances externes. Cela réduit les hallucinations et garantit des réponses plus précises et factuelles, particulièrement utiles pour les assistants techniques et les systèmes d’aide à la décision.
Contrairement aux approches RAG classiques qui se contentent de récupérer des documents et de les transmettre à un LLM, un Agentic RAG va plus loin : il intègre des mécanismes de prise de décision, de filtrage et de reformulation intelligente des requêtes. L’objectif ? Optimiser la pertinence des informations remontées et réduire les erreurs potentielles.
Dans notre projet, un simple RAG ne suffisait pas : les articles de presse contiennent souvent des informations complexes et parfois ambiguës, nécessitant une meilleure compréhension contextuelle avant d’être exploités. Pour pallier ces limitations, nous avons adopté une approche Agentic RAG, capable d’améliorer la pertinence des réponses et de limiter les erreurs grâce à une combinaison de plusieurs techniques :
Architecture du système Agentic RAG
- Chargement et segmentation des articles de presse
- Extraction des textes pertinents
- Découpage en segments pour une meilleure indexation
- Vectorisation des documents
- Utilisation d’embeddings pour représenter le sens des textes
- Stockage dans une base de données vectorielle (ex. FAISS, ChromaDB)
- Agent de récupération intelligent
- Reformulation des requêtes pour améliorer la pertinence
- Filtrage des résultats pour éviter les informations non pertinentes
- Intégration avec un LLM via API
- Génération de réponses basées sur les documents récupérés
- Vérification de la cohérence et de la fiabilité des réponses
- Orchestration avec LangChain et LangGraph
- Mise en place d’un workflow dynamique pour gérer les interactions
- Utilisation de LangGraph pour structurer les étapes de récupération et de génération
Le résultat ? Un assistant capable de répondre aux questions sur le contenu des articles de presse en citant ses sources. C’est bien plus puissant et précis qu’un simple appel d’API.
🔹L’art du prompt : une compétence critique
Prompter une IA, ce n’est pas juste poser une question.
Les clés d’un prompt efficace :
- Précision et concision : Être clair sur le rôle, la tâche, le format et le ton souhaités.
- Contextualisation : Fournir toutes les informations nécessaires à l’IA pour comprendre la demande.
- Contraintes et exemples : Définir les limites de la réponse et donner des exemples de ce qui est attendu.
- Itération et expérimentation : Ajuster le prompt en fonction des résultats obtenus.
Voici un exemple de prompt système que j’ai développé pour un chatbot littéraire, illustrant les bonnes pratiques pour guider efficacement l’IA dans la recherche et la présentation d’informations :
PROMPT SYSTÈME :
Tu es un assistant littéraire spécialisé dans la recherche d’informations à partir de documents fournis ou via des outils de recherche web. Ton rôle est de répondre aux questions des utilisateurs concernant des œuvres littéraires, des auteurs ou des concepts littéraires.
RÈGLES IMPORTANTES :
RÈGLES IMPORTANTES :
- Utilise en priorité les informations contenues dans les documents fournis (CONTEXTE).
- Si l’information n’est pas disponible dans le contexte, utilise l’outil de recherche web pour trouver des réponses pertinentes.
- Cite toujours tes sources (nom du fichier ou URL) si tu utilises des informations externes.
- Tes réponses doivent être concises (max 3 paragraphes) et informatives.
- Si tu ne trouves pas d’information pertinente, dis-le clairement.
FORMAT DE RÉPONSE :
- Commence par une phrase confirmant la compréhension de la question.
- Présente les informations trouvées de manière claire et structurée.
- Indique la source des informations.
- Si pertinent, propose des pistes de recherche supplémentaires.
EXEMPLE DE RÉPONSE :
Question de l’utilisateur : « Qui est le personnage principal de ‘Madame Bovary’ ? »
Réponse de l’IA :
« Vous demandez des informations sur le personnage principal de ‘Madame Bovary’.
Le personnage principal de ce roman de Gustave Flaubert est Emma Bovary, une femme mariée qui rêve d’une vie romanesque et passionnée, inspirée par ses lectures. Ses désillusions et ses tentatives pour échapper à la monotonie de son existence sont au cœur du récit.
Source : Connaissance générale sur l’œuvre. »
CONTEXTE : {context} (informations littéraires provenant de fichiers)
Ce prompt met en évidence la définition du rôle d’assistant littéraire :
- l’importance de la priorisation des sources d’information,
- la citation des sources,
- un format de réponse informatif et structuré,
- la gestion des cas où l’information n’est pas trouvée.
- L’intégration d’un outil de recherche web (tool) est également prise en compte dans les règles.
Ce prompt illustre parfaitement les bonnes pratiques :
- Définition claire du rôle
- Instructions précises sur le format attendu
- Exemples concrets
- Mécanisme pour intégrer le contexte (documentation)
La qualité des réponses générées par une IA ne repose pas seulement sur son modèle, mais aussi sur la précision de son prompt. Un bon prompt peut transformer une réponse floue en une assistance efficace et ciblée.
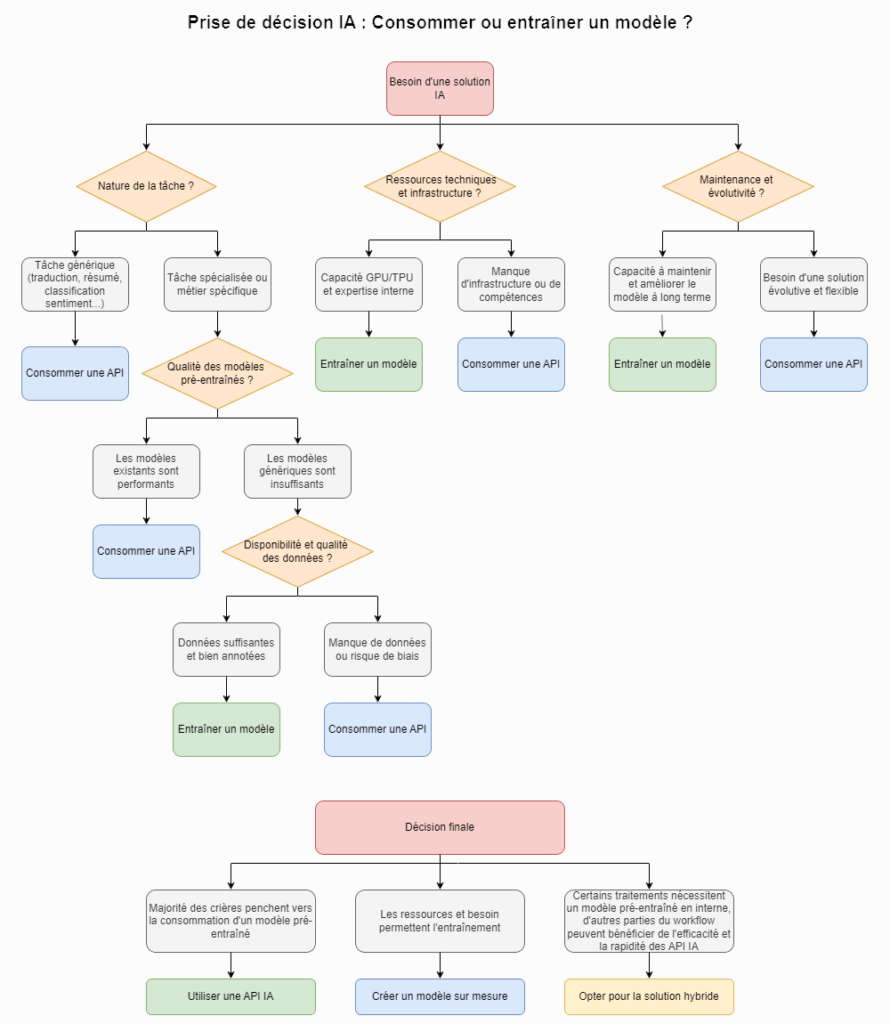
🔹 Entraîner ou consommer : un choix stratégique
Entraîner un modèle reste indispensable pour certains cas d’usage (santé, industrie, finance…). Mais cela demande des moyens importants. Beaucoup d’entreprises préfèrent donc consommer l’intelligence déjà disponible. Savoir entraîner un modèle reste utile — surtout pour comprendre comment le manipuler intelligemment.
Quand privilégier l’entraînement d’un modèle personnalisé ?
- Données sensibles
- Problèmes très spécifiques
- Besoin de contrôle total
- Volume de traitement
- Évolution des pratiques
L’entraînement d’un modèle personnalisé est indispensable lorsque les données sont sensibles et ne peuvent pas sortir de l’infrastructure de l’entreprise. Cela garantit une meilleure confidentialité et conformité réglementaire.
Pour les problèmes très spécifiques, les modèles génériques peinent parfois à comprendre le contexte métier. Dans ces cas, un modèle conçu sur-mesure améliore la pertinence des prédictions et l’adaptation aux besoins précis.
Un autre facteur clé est le besoin de contrôle total. Certaines entreprises doivent pouvoir auditer le fonctionnement du modèle, expliciter ses décisions ou garantir une traçabilité complète des données.
Le volume de traitement peut aussi rendre l’utilisation d’API IA coûteuse. À grande échelle, entraîner un modèle interne devient plus économique et permet d’éviter une dépendance excessive aux fournisseurs externes.
Enfin, avec l’évolution des pratiques, de nombreux acteurs adoptent des modèles open-source performants et les entraînent sur leurs propres données. Cette approche renforce la maîtrise technique et réduit les risques liés aux changements de conditions des API externes.
Quand privilégier la consommation d’API ?
- Time-to-market
- Fonctionnalités génériques
- Expérimentation
- Ressources limitées
L’IA pré-entraînée via API permet de réduire le délai de mise en production. Plutôt que de passer des mois à entraîner un modèle sur mesure, une entreprise peut rapidement intégrer une solution existante pour répondre à un besoin immédiat. C’est un choix stratégique pour les projets où la rapidité de déploiement est essentielle.
Les fonctionnalités génériques comme la traduction, la classification de sentiment ou la génération de texte sont souvent bien couvertes par des modèles pré-entraînés. Cela évite d’avoir à créer et entraîner un modèle personnalisé, optimisant ainsi les coûts et l’efficacité.
Les API IA sont également un excellent outil d’expérimentation. Elles permettent de tester un cas d’usage avant d’investir dans une solution sur mesure, facilitant la validation de faisabilité et l’intérêt du projet sans immobiliser trop de ressources.
Enfin, pour les entreprises avec des ressources limitées—peu de budget, absence d’infrastructure GPU, ou manque de compétences internes—les API offrent une solution accessible sans la complexité technique liée à l’entraînement d’un modèle.
L’hybridation des modèles
En réalité, beaucoup d’entreprises adoptent une approche hybride : elles exploitent des API pour les tâches courantes et entraînent leurs propres modèles lorsque les exigences métier imposent une personnalisation ou une maîtrise totale.
Si la décision d’entraîner ou de consommer un modèle IA repose sur des critères techniques et stratégiques, elle est aussi fortement influencée par des considérations économiques. Derrière chaque option se cachent des coûts parfois sous-estimés, qui impactent directement la rentabilité d’une solution IA.
🔹 La maintenance : le coût caché des modèles
Un aspect souvent négligé est la maintenance des modèles d’IA. Une fois déployé, un modèle n’est pas immuable. Il doit être surveillé, évalué et parfois réentraîné pour maintenir ses performances.
Pour un modèle entraîné en interne, cela signifie :
- Mettre en place un monitoring des performances
- Détecter la dérive conceptuelle
- Réentraîner périodiquement avec de nouvelles données
- Gérer les versions du modèle
- Instaurer des pratiques MLOps (Machine Learning Operations)
Un modèle IA entraîné en interne nécessite un suivi rigoureux des performances pour garantir qu’il reste pertinent au fil du temps. Cela inclut la surveillance de métriques clés et l’ajustement des paramètres si la qualité des prédictions baisse.
La dérive conceptuelle (concept drift) est un risque majeur. Si la distribution des données évolue, le modèle peut devenir progressivement obsolète. Par exemple, un modèle de prédiction boursière basé sur des tendances historiques pourrait perdre en efficacité face à des changements brusques du marché.
Le réentraînement périodique avec de nouvelles données permet d’adapter le modèle aux évolutions récentes et de préserver sa fiabilité.
La gestion des versions est essentielle pour suivre les différentes itérations du modèle, comparer les performances et revenir à une version précédente en cas de problème.
Enfin, l’intégration de pratiques MLOps permet d’automatiser une partie de ces tâches, en assurant un suivi continu des performances et en déclenchant des réentraînements basés sur des seuils définis.
Pour les API d’IA, la maintenance est différente, mais tout aussi importante :
- Surveiller les changements d’API et de pricing
- Adapter les prompts aux nouvelles versions des modèles
- Tester régulièrement les cas critiques pour détecter les régressions
- Prévoir des solutions de fallback (plan de secours) en cas dysfonctionnement, indisponibilité ou échec d’une API
Un modèle IA n’est jamais un produit fini : sa maintenance implique des coûts en infrastructure, en expertise et en mise à jour des données. Pour les solutions basées sur API, il faut anticiper les variations de tarification et les évolutions technologiques imposées par le fournisseur.
🔹 Les coûts réels de l’intelligence artificielle
Au-delà de la maintenance et des coûts cachés, l’IA représente un investissement lourd en infrastructure et en puissance de calcul. Selon l’approche choisie, ces coûts peuvent varier considérablement :
- Coût du stockage et de l’infrastructure
- Puissance de calcul et ressources GPU
- Coût des licences et outils spécialisés
- Consommation énergétique et empreinte écologique
Les modèles entraînés en interne nécessitent une capacité de stockage importante pour héberger les jeux de données, les checkpoints et les versions du modèle. Cela implique souvent des serveurs dédiés ou des solutions cloud, dont les coûts peuvent rapidement grimper.
L’entraînement d’un modèle IA exige une puissance de calcul massive, notamment pour les modèles deep learning. Les GPU (voire TPU) sont essentiels pour accélérer ces calculs, mais leur coût d’acquisition et d’utilisation peut être prohibitif.
Certaines plateformes proposent des environnements d’entraînement optimisés (comme Azure ML, AWS SageMaker, Google Vertex AI). Si elles simplifient le processus, elles impliquent des frais d’abonnement et parfois des coûts liés à l’usage des API internes , ce qui peut alourdir le budget à grande échelle..
Enfin, un facteur souvent sous-estimé : l’impact énergétique des entraînements IA. Les data centers consomment énormément d’électricité, et certains modèles nécessitent des milliers d’heures de calcul, augmentant l’empreinte carbone.
À l’inverse, utiliser une API IA permet d’externaliser ces coûts. L’entreprise paie à l’usage (ex. coût par token), sans avoir à gérer l’infrastructure ou la consommation énergétique. Mais attention aux frais cachés : le volume de requêtes peut rapidement rendre l’option plus coûteuse que prévu !
🔹 L’IA est un outil, pas une promesse magique
Ce que je retiens de ces expériences, c’est que développer une application IA, ce n’est pas uniquement coder un modèle de deep learning. C’est avant tout répondre à un besoin : automatiser une tâche, extraire une information, prédire un comportement, etc. Et pour y parvenir, le modèle ne fait pas tout. Il faut penser l’architecture globale, l’interface, les entrées-sorties, la sécurité des données, la logique métier, les cas limites, l’évolutivité…
Autrement dit, l’IA n’est pas une fin en soi. C’est un composant d’un système plus vaste.
Concevoir une solution IA efficace, c’est donc bien plus que créer un modèle performant : un modèle d’IA, aussi avancé soit-il, n’a de valeur que s’il s’intègre efficacement dans un écosystème technique et métier. Il doit cohabiter avec des bases de données, des API, des systèmes de gestion et des outils d’analyse pour produire un réel impact.
Et que ce composant soit entraîné maison ou appelé via API, ce qui compte, c’est de savoir comment l’intégrer intelligemment.
🔹 Une compétence à part entière : choisir le bon niveau d’IA
Finalement, savoir coder un modèle, c’est essentiel pour comprendre les mécanismes sous-jacents. Mais dans la pratique, la véritable compétence d’un développeur IA, c’est de savoir choisir la bonne solution pour le bon usage. Est-ce qu’un modèle pré-entraîné suffit ? Faut-il l’affiner avec des données spécifiques ? Faut-il entraîner un modèle sur mesure ? Ou bien s’en passer complètement et recourir à des règles simples ?
C’est cette prise de recul qui m’intéresse aujourd’hui.
L’IA est un champ passionnant, mais exigeant. Elle oblige à naviguer entre la rigueur du code, la maîtrise des données, la connaissance métier… et une certaine humilité face à des outils aussi puissants qu’imprévisibles.
Maîtriser l’IA, ce n’est pas chercher à la dompter totalement, mais apprendre à guider son imprévisibilité tout en acceptant qu’elle conserve une part d’autonomie. Comme un cheval fougueux, elle peut surprendre, mais au lieu de vouloir tout contrôler, il faut savoir lâcher prise sur certains aspects tout en mettant en place des garde-fous pour canaliser son énergie et orienter ses réponses intelligemment.
Et si demain, le rôle des développeurs IA n’était plus de créer des modèles, mais de les comprendre, les assembler, et les encadrer ?