Avant de commencer, cet article est la suite de l’article sur la création de modèles avec scikit-learn. Je vais reprendre beaucoup de concepts que j’ai expliqués dans cet article et surtout beaucoup de code. Même si je vais réexpliquer mon code, je le ferai plus brièvement. Si vous souhaitez avoir des explications supplémentaires, je vous conseille vivement de lire mon article précédent sur scikit-learn et celui sur l’introduction au Machine Learning. Maintenant que les bases sont posées, commençons !
Qu’est ce que la cross-validation ?
La cross-validation, ou validation croisée en bon Français, c’est une méthode d’entrainement qui consiste à entraîner plusieurs fois un modèle sur le même dataset, mais en changeant à chaque fois le jeu d’entraînement et de test (qui provienne du coup de différentes parties du dataset). On mesure ensuite le score de test de chacun des modèles entraînés et on fait une moyenne pour mesurer la performance de l’algorithme. Entre chaque entraînement, le modèle est naturellement réinitialisé, pour éviter qu’il apprenne tout le dataset.
L’objectif de ces différents entraînements est d’être sûr que la méthode qu’on a utilisée est correcte, et que le split des données, entre jeu d’entraînement et jeu de test n’a pas été favorable à un algorithme ou à un autre. Pour le dire autrement, le but est d’être sûr que le modèle a bien généralisé le problème qu’il essaie de résoudre, et que les mesures de performances en rendent bien compte.
La manière dont le jeu de données est séparé lors d’une cross-validation, dépend de la stratégie de cross-validation que l’on choisit. Il y a, en effet, plusieurs manières de séparer un jeu de données et le choix de la stratégie dépend du jeu de données et de ce que l’on veut faire. Cet article va couvrir les plus communes.
Une précision néanmoins, vous l’avez peut-être déjà compris, mais le but de la validation croisée n’est pas d’améliorer les performances de notre modèle, mais bien de mesurer de manière plus fiable ses performances pour les comparer plus précisément avec d’autres modèles.
Notre modèle et jeu de données
Comme pour l’article précédent, mon jeu de données sera l’Adult Census Income. Cela nous permettra de retrouver des repères pris précédemment, notamment sur l’objectif du modèle. En effet, le modèle aura le même but, déterminer, à partir des informations qu’on a, si le salaire de la personne est supérieur ou non à $50k par an.
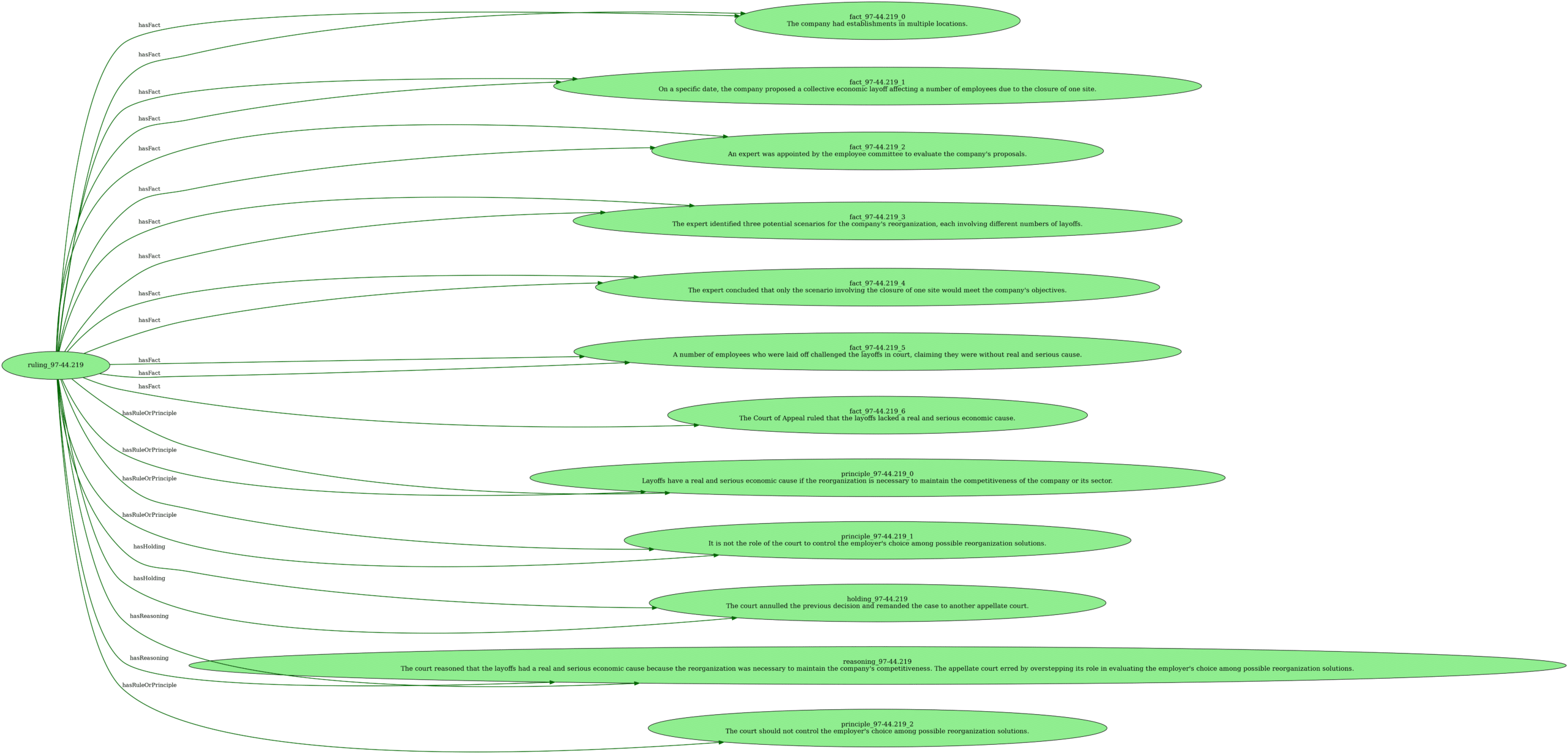
Pour le modèle, nous allons changer un peu l’algorithme, je vais utiliser une Random Forest, une forêt aléatoire. Sans nécessairement rentrer dans le détail, une fôret aléatoire est un ensemble d’arbres de décisions, qui sont entrainés chacun sur une petite partie des données, et le modèle prend sa décision en faisant une moyenne des réponses des arbres de décisions. Voici donc le modèle qui va servir de base pour la cross-validation :
Ce modèle est donc une forêt aléatoire, et le modèle prend soin de prétraiter les données numériques et catégoriques pour normaliser les premières et numériser les secondes.
Bref rappel
Dans le premier article pour entrainer le modèle, nous utilisions la fonction train_test_split qui séparait le jeu de données en 2 jeux.

Cette fonction sépare aléatoirement le dataset en jeu d’entraînement et de validation. Cette séparation a beau être aléatoire, elle peut néanmoins être biaisée, en créant des déséquilibres de données qui peuvent soit rendre notre modèle moins performant ou au contraire le favoriser.
Le but des modèles que l’on crée est de généraliser les règles permettant de déduire de nos entrées, la cible, et de s’adapter aux nouvelles données. Il est donc important que la mesure des performances soit la plus précise et neutre possible, en éliminant le plus de biais éventuels.
Validation croisée par K-blocs
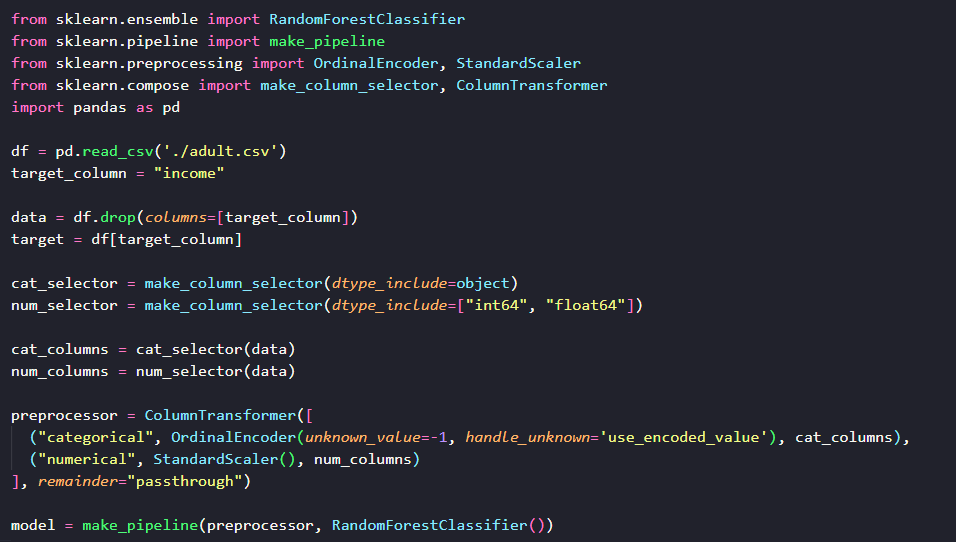
La première stratégie de cross-validation que nous allons voir est la stratégie par K-blocs (ou KFold en anglais). Le principe est simple, on va diviser le dataset en K-parties, où K est un nombre entier qu’on choisit à l’avance (entre 5 et 10 en général), et on va entraîner K modèles avec à chaque fois 1 partie du dataset qui sert de jeu de test, et les autres parties qui servent de jeu d’entrainement. La partie qui sert de jeu de test n’est jamais la même, évidemment.
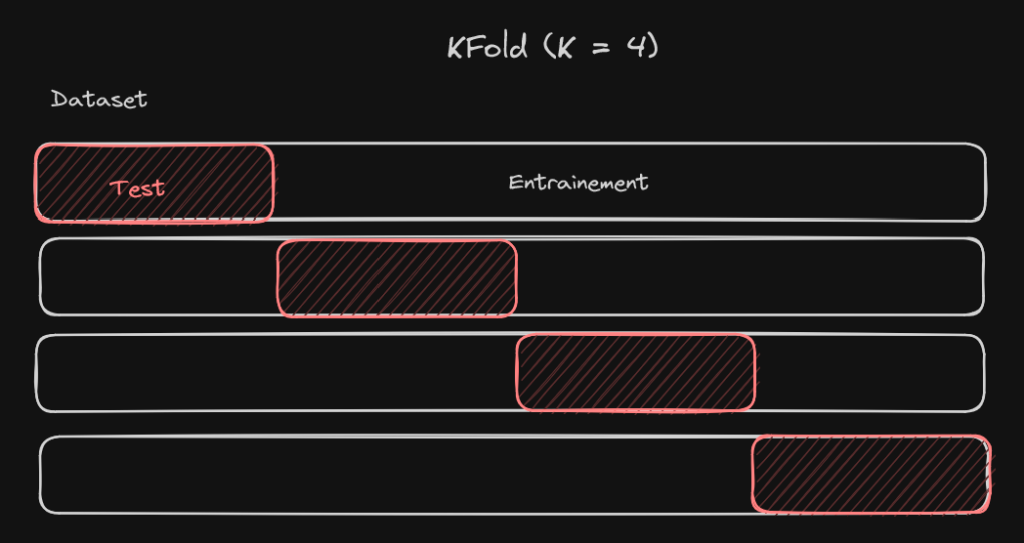
Comment implémente-t-on ça avec scikit-learn ? La première chose à savoir, c’est comment faire une validation croisée. Pour cela, il y a la fonction cross_validate qui permet de faciliter ce processus. Ensuite, pour le KFold, il y a la classe KFold qui permet de créer ces différentes segmentations du dataset.
Par défaut, la méthode cross_validate retourne 3 informations par splits : le temps d’entraînement, le temps pour mesurer le score et le score de test.
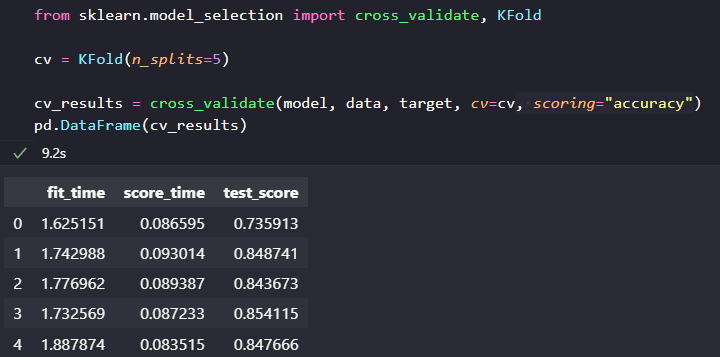
Dans le code ci-dessus, vous pouvez voir comment on effectue une cross-validation. D’abord, on crée la stratégie avec, ici, la classe KFold. Le paramètre n_splits indique le nombre de parties du dataset que l’on crée (ce que j’ai appelé K jusque maintenant).
Ensuite, on appelle la fonction cross_validate, qui prend en pramètre le modèle, les données, et la cible. On spécifie ensuite le cv, qui est la stratégie de validation croisée que l’on veut, et on peut ensuite aussi préciser la métrique de score avec le paramètre scoring. Ce dernier paramètre peut être une chaine de caractères prédéfinie par scikit-learn ou une fonction de score.
On récupère ensuite les résultats, que j’ai convertis ici en DataFrame pour les manipuler plus facilement. On peut ainsi voir ici, le score de chaque instance du modèle entrainé.
Plutôt facile, non ? Maintenant que nous avons vu la base, nous allons pouvoir voir d’autres stratégies.
La séparation par K-blocs stratifiés
Le principe de séparation par K-blocs stratifiés est légèrement différent de celui par K bloc, et il s’applique uniquemen pour des problèmes de classification. L’objectif de cette séparation va toujours être de créer K parties du dataset, mais ce coup-ci, on va vouloir que chaque partie, chaque bloc, contiennent la même répartition de données. Je m’explique, reprenons notre dataset, l’Adult Census Income. Ce dataset contient les données de 32 000 foyers américains. Parmi ces foyers, 76% d’entre eux ont un revenu en dessous de $50K, et 24% au dessus de $50K. La séparation en K-blocs stratifiés va faire en sorte que dans chaque bloc, il y ait 76% de foyers avec un revenu en dessous de $50K et 24% au dessus de $50K.
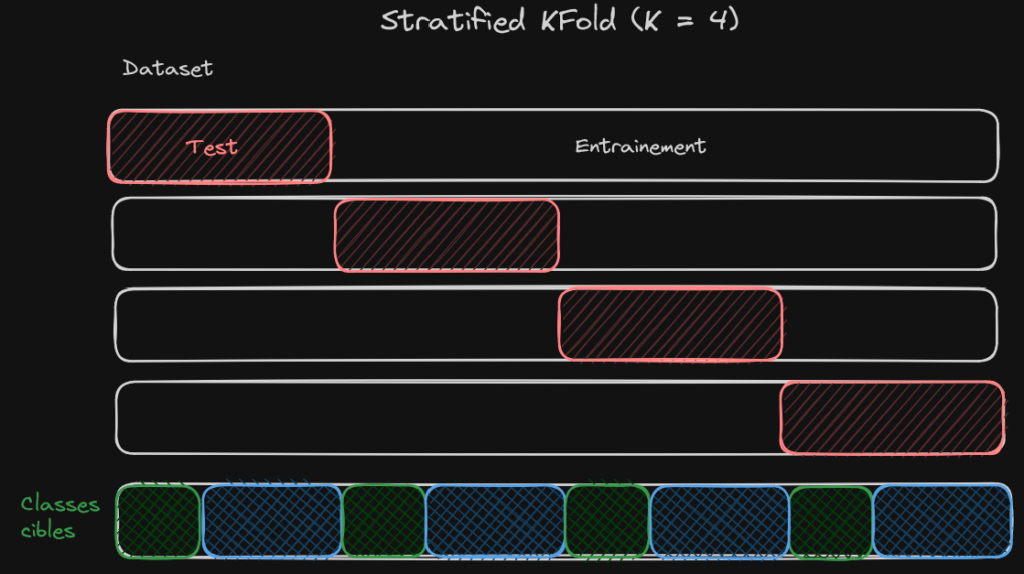
Cela garantit que toutes les données sont correctement représentées dans chacun des blocs. Mais cela suppose aussi que le dataset représente correctement les données que nous allons rencontrer en production (ce qui devrait être le cas, mais ne l’est pas toujours).
Passons à l’implémentation, et comme toujours, scikit-learn a une classe pour nous aider : StratifiedKFold. Et elle s’utilise de la manière suivante :

Comme pour la séparation en K-blocs, StratifiedKFold prend un paramètre n_splits qui permet de définir le nombre de blocs que nous souhaitons créer. Le reste du code est similaire.
Juste une petite précision sur le contenu du print : une manière de présenter les résultats d’un cross-validation est d’afficher la moyenne des scores de tests avec une marge d’erreur correspondant à l’écart-type des résultats. Cela permet de présenter simplement les données et les comparer facilement.
Une autre chose que je souhaite vous montrer avec la méthode cross_validate, c’est que le paramètre cv accepte aussi comme valeur des entiers. La stratégie de split utilisée sera alors la séparation par K-blocs stratifiés pour les classifications et une simple séparation par K-blocs pour les régressions.
La séparation aléatoire
La séparation aléatoire, comme son nom l’indique, va séparer, pour chaque instance de modèle, le jeu de données aléatoirement entre jeu d’entraînement et jeu de test. On doit définir 2 choses : le nombre de séparations que l’on souhaite faire et la taille du jeu de test.
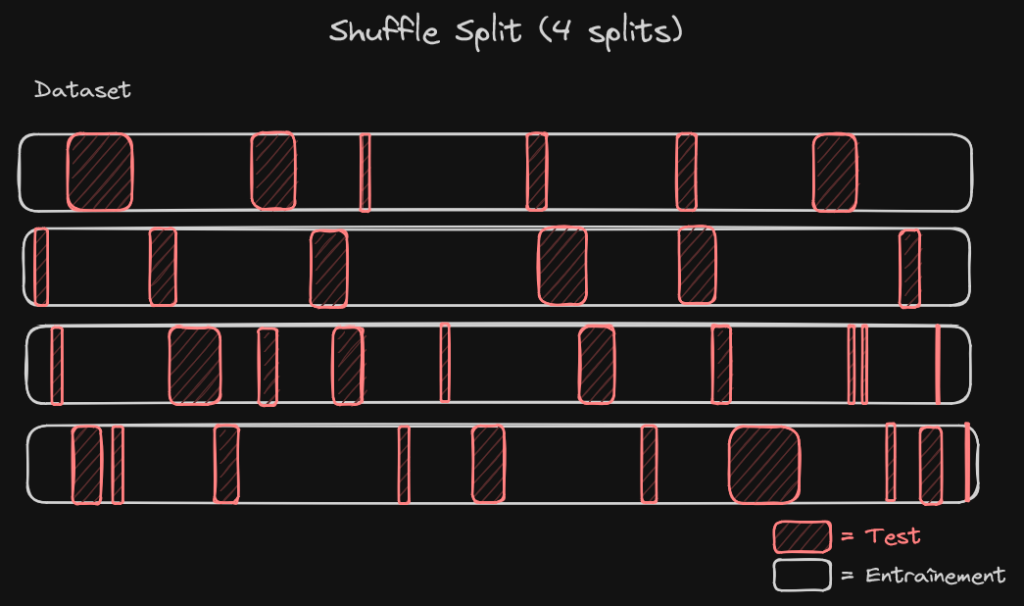
Dans scikit-learn, la classe qui implémente ça est ShuffleSplit et elle s’implémente de la façon suivante :

Ici, on va entraîner 10 modèles avec une séparation 80/20 des données entre jeu d’entraînement et jeu de test. Le reste du code reste le même.
Conclusion
La validation croisée est un processus qui permet de comparer de manière plus précise et fiable, les différentes architectures de modèles, en réduisant les biais qui peuvent être associés à la séparation des jeux d’entraînement et de test. Le mécanisme principal mis en jeu lors de ce processus, est d’entrainer plusieurs modèles avec des jeux d’entraînement et de test différents, même s’ils restent issus du même dataset.
Il existe beaucoup de stratégies possibles pour séparer les données lors de la cross-validation, cet article en couvre 3, mais scikit-learn en propose bien d’autres. Vous pouvez les retrouver dans leur documentation.