Dans mon article précédent, j’avais abordé les fondamentaux du Machine Learning , les bases de cette discipline pour créer des modèles d’IA. Aujourd’hui, je veux vous montrer comment créer ces modèles avec une des librairies les plus utilisées pour faire du Machine Learning, scikit-learn.
Présentation de Scikit-Learn et son écosystème
Scikit-Learn est une librairie libre et open-source développée en Python qui permet de créer et d’entraîner différents modèles de Machine Learning. La librairie s’inclut dans l’écosystème des librairies comme pandas, numpy ou scipy qui sont utilisées pour faire de la manipulation de données, des calculs, de l’analyse statistique, probabiliste, etc… Chacune de ces librairies mériterait qu’on les introduise un peu plus longuement, mais je vais me contenter d’expliquer ce que j’en utilise. Peut-être que pandas, numpy et scipy feront l’objet d’un prochain article…
Scikit-Learn est maintenu par le scikit-learn consortium centré autour de l’Inria et de plein d’acteurs du monde de l’IA comme Nvidia ou Hugging Face. Elle offre tout un ensemble d’outils pour créer des modèles et mesurer leurs performances. Pour les présenter, je vais passer par l’exemple, où on va commencer par créer un modèle simple que nous pourrons l’améliorer dans de futurs articles.
Le dataset « Adult Census Income »
Avant de vouloir créer un modèle, il faut d’abord charger des données et savoir quel problème on veut résoudre. J’ai choisi de prendre, pour l’exemple, le dataset « Adult Census Income » qui est un échantillon du census américain de 1990. C’est un dataset connu dans le monde du Machine Learning, il a été utilisé dans des recherches sur le sujet. Avant de poursuivre, je vous invite à vous renseigner sur ce qu’est le census américain, et sur le contenu du dataset.
L’objectif de ce dataset est de deviner la catégorie de salaire d’une personne en fonction des données recensées (catégorie sociale, niveau d’éducation, son âge, etc…). Le dataset ne connait que 2 niveaux de salaires : « plus de $50K » et « $50K ou moins ».
Pour charger le dataset et pouvoir ensuite le manipuler, nous allons devoir utiliser pandas :

Ici, on importe la librairie pandas, et on utilise la fonction read_csv pour lire les données et les stocker dans la variable df. df, c’est l’abréviation de DataFrame, ce qui est une structure qui permet de stocker et de manipuler des données sous forme de tableau, des données tabulaires. Regardons un peu ce qu’il contient :


La fonction head permet d’afficher les 5 premières lignes du dataframe. On distingue deux types de variables, des variables qualitatives, qui indiquent une catégorie (par exemple sex, education, native.country, etc…) et des variables quantitatives, qui indiquent des quantités (par exemple capital.loss, hours.per.week, age).
Les variables quantitatives, de par leur nature, sont nécessairement représentées par des nombres. Mais toutes les variables numériques présentes dans un dataset ne sont pas nécessairement quantitatives. Par exemple, ici « education.num » contient un nombre qui correspond au niveau d’éducation qui est une variable qualitative. Elle permet juste d’ordonner les niveaux entre eux.
Choisir notre algorithme de ML
Maintenant qu’on a nos données, on va devoir choisir notre algorithme. Il faut alors déterminer quel type de problème on résout, une classification ou une régression ?
Un algorithme de classification permet de prédire une variable qualitative, de classer, ranger dans des petites boîtes, nos données en un nombre fini de classes. À contrario, un algorithme de régression aura pour but de prédire une variable quantitative. Le résultat sera alors un nombre qui ne sera pas nécessairement borné et qui pourra être aussi précis que l’on souhaite.
Ici, on veut prédire si le salaire de la personne est au dessus ou en dessous de $50K, on a donc 2 catégories possibles, c’est donc un problème de classification.
Il existe plein de types d’algorithmes de classification, qui fonctionnent de manière différente, mais pour ce premier modèle, nous allons entrainer un arbre de décision.
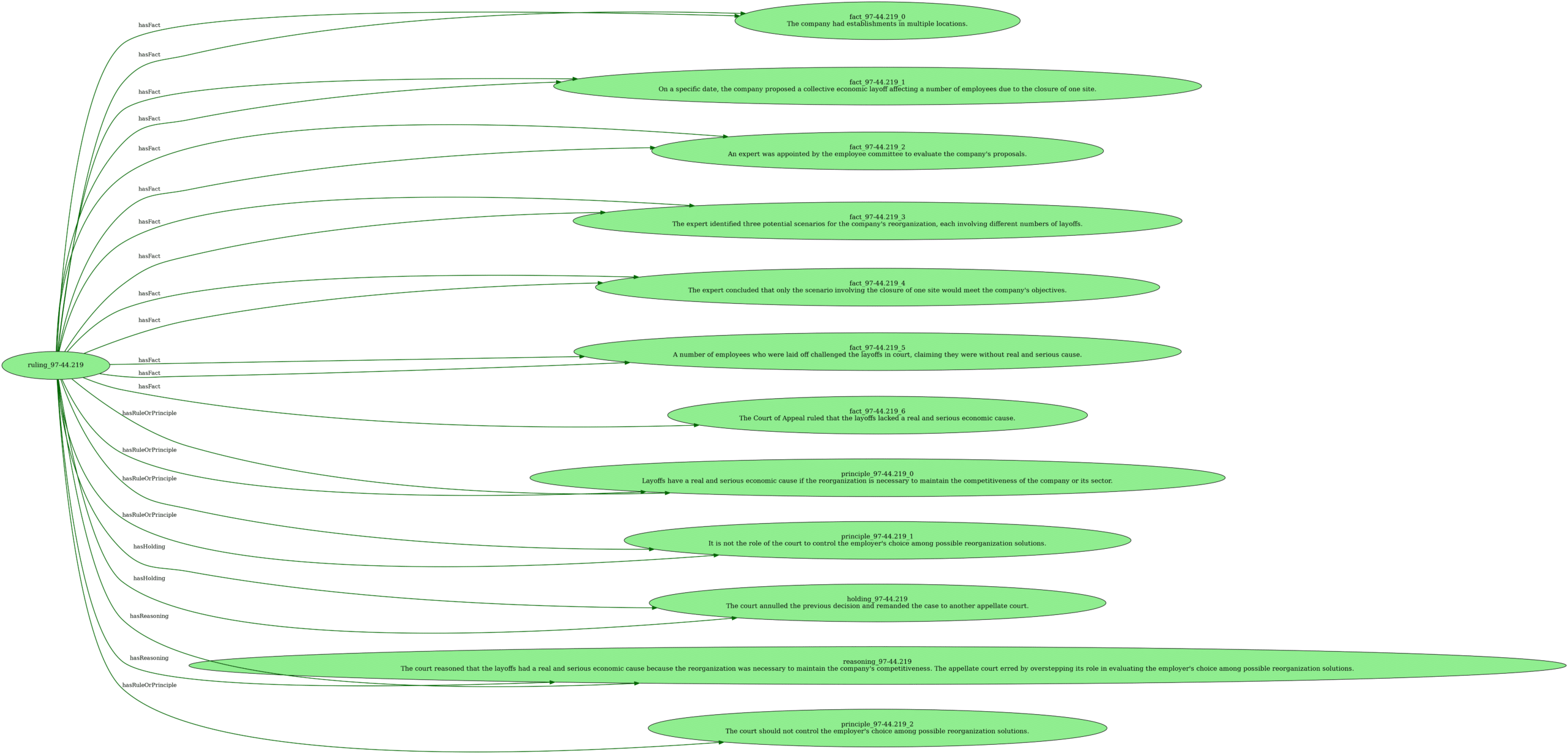
Le principe de l’arbre de décision est de construire, pendant l’entrainement, un arbre avec à chaque nœud, une condition. Si la condition est valide, alors on passe au nœud qui correspond, sinon, on passe à l’autre. À la fin de chaque chemin de l’arbre, il y a une catégorie qui est la valeur qui sera renvoyée si l’échantillon de données a suivi ce chemin.
L’implémentation avec scikit-learn
Bien assez avec les explications, passons au code ! D’abord, il faut séparer les données de la cible. Pour des raisons d’implémentations, les arbres de décisions de scikit-learn ne supportent que les valeurs numériques. Nous allons donc ne prendre que les colonnes qui ont des nombres.

Grâce à pandas, il nous suffit de mettre le nom des colonnes que l’on veut récupérer entre crochets dans le dataframe et on a récupéré les données que l’on souhaitait. Maintenant que nous avons nos données et notre cible, il faut qu’on les sépare en jeu d’entraînement et de validation. Pour cela, on va utiliser la fonction train_test_split qui va faire cette séparation pour nous.

Cette fonction prend au moins 2 paramètres, les données et la cible, et il renvoie les données et les cibles séparées en 2 jeux. J’ai utilisé des paramètres supplémentaires qui me permettent de mieux contrôler la séparation. test_size permet de définir la proportion des données de test. Ici, je l’ai mise à 30 %. random_state permet de choisir la seed de la séparation aléatoire. La fixer à 0 me permet de m’assurer que mes jeux de données d’entraînement et de test auront toujours les mêmes données.
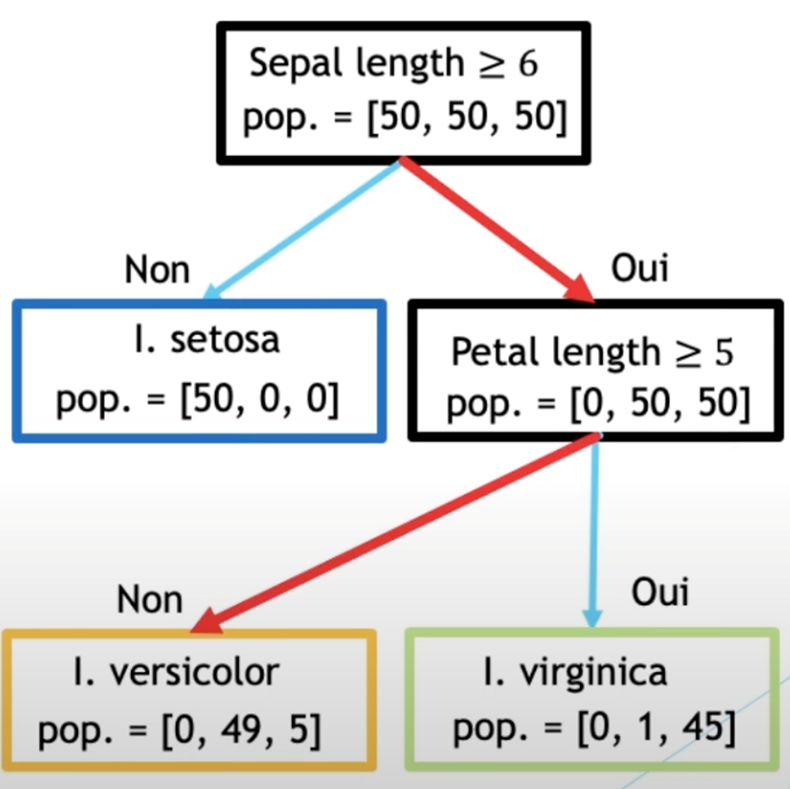
Maintenant créons notre modèle. Pour cela, nous allons utiliser la classe DecisionTreeClassifier. Cette classe nous permet de créer un arbre de décision qui va pouvoir classifier les données qu’on lui passe.
Ce code crée le modèle et le paramètre max_depth, permet de contrôler la profondeur maximum de l’arbre : il y aura 3 niveaux de conditions maximum. La méthode fit permet de l’entraîner avec nos données d’entraînement. Cette méthode est commune à tous les modèles de scikit-learn. Cela permet de standardiser l’API des modèles.
On peut ensuite mesurer les performances du modèle créé avec la méthode score.


Donc, on peut voir que le score se mesure à l’aide du jeu de test, et on voit que notre modèle a une exactitude de 80 %. C’est un modèle correct, mais il est améliorable. À noter qu’il existe énormément de métriques de score différentes et qui varient en fonction du type de problème. C’est un vaste sujet, mais si vous souhaitez commencer à l’aborder, je vous conseille de jeter un œil à la documentation de sklearn.metrics. Cela vous permettra de voir quelles sont ces métriques et comment elles fonctionnent.
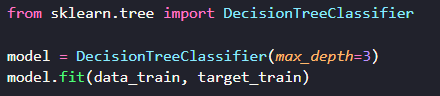
Si on veut voir l’arbre de décision généré, on peut utiliser la fonction plot_tree pour afficher l’arbre. On aura besoin de la librairie matplotlib pour l’afficher correctement.
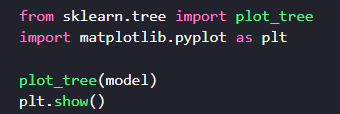
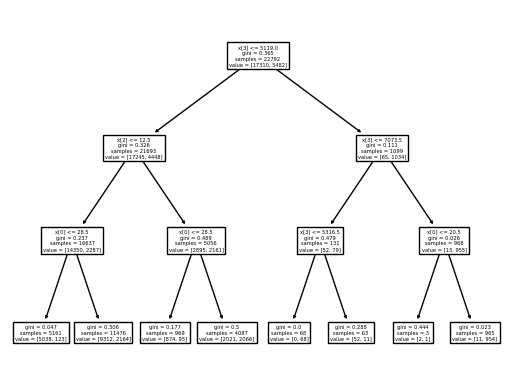
Sur ce diagramme, vous pouvez voir les conditions et comment elles s’enchainent. On a aussi l’information de combien de données dans le jeu d’entrainement tombent dans ces cas, et de leur répartition. La valeur gini correspond au score de pureté de chaque séparation. Le score de pureté indique la qualité de la séparation. Plus le score est haut, plus il sépare de manière nette les 2 cibles de notre problème.
Et les variables qualitatives là-dedans ?
Dans l’exemple que j’ai donné avant, on a pré-sélectionné les données qui sont des nombres, mais comment peut-on inclure les autres ? On va avoir besoin de traiter les données avant de les donner au modèle. Ça tombe bien, scikit-learn fournit un ensemble de classes et de fonctions qui permettent de sélectionner et de prétraiter les données.
Avant, il va falloir redéfinir nos données. On va reprendre le dataframe initial df et ce coup-ci, on va juste lui retirer la cible.
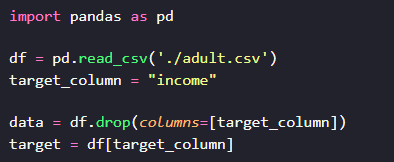
La fonction drop permet de retirer des colonnes du dataframe. Il ne modifie pas le dataframe initial, mais il retourne la version sans les colonnes indiquées par le paramètre columns. Ensuite, il va falloir qu’on détecte les colonnes non numériques. Pour cela, on va utiliser la fonction make_column_selector.

Cette fonction est un peu particulière, car elle prend un paramètre dtype_include, qui correspond aux types de paramètres qu’elle peut prendre et elle nous retourne une fonction qui va prendre en paramètre un dataframe. Ici, on lui dit de nous retourner les colonnes avec un type object qui correspond aux chaines de caractères. Une liste des dtypes (qui est l’abréviation de data types) est disponible sur la documentation de pandas.
On a ensuite appliqué le sélecteur sur notre dataframe qui a extrait le nom des colonnes de type object. Voici ce que contient la variable cat_columns

Maintenant qu’on a fait ça, on va pouvoir passer à la prochaine étape : créer un pré-processeur. Le pré-processeur va nous permettre de transformer nos données avant de les passer au modèle. Pour cela, on va utiliser 2 classes : OrdinalEncoder, qui va permettre de convertir nos chaines de caractères en nombres, en leur assignant une valeur entre 1 et le nombre de chaines de caractères différentes dans l’échantillon et ColumnTransformer, qui va nous permettre de traiter différemment les colonnes de type object et les autres.

Décryptons un peu ce préprocesseur : le ColumnTransformer prend en paramètre une liste de tuples. Chaque tuple est composé de 3 éléments : le nom de l’étape (ce qui est utile quand on veut visualiser le pré-processeur), le traitement qu’on veut effectuer, et la liste des colonnes qui sont affectées par ce pré-processeur. Le paramètre remainder, indique ce que l’on fait avec le reste des colonnes qui n’ont pas été transformées. Ici, on indique qu’on les laisse tels quels, on aurait pu les abandonner.
Pour l’OrdinalEncoder, on lui dit que s’il croise des valeurs inconnues, alors on leur attribue la valeur -1. C’est parce que la séparation des données peut avoir séparé des classes rares dans notre dataset.
Maintenant qu’on a notre préprocesseur, on va pouvoir l’utiliser et le brancher à notre modèle avec la fonction make_pipeline. Cette fonction nous permet de chainer des étapes dans lesquelles vont passer nos données et de traiter le tout comme un modèle. On pourra entraîner et mesurer les performances de notre modèle.

On sépare de nouveau nos données et on crée le pipeline, avec d’abord le préprocesseur puis le modèle. Puis on entraîne le modèle avec la méthode fit, comme précédemment. Si on regarde maintenant les performances de notre modèle :


Le modèle est monté à une exactitude de presque 84 %, soit 4 points de plus que sans les données non numériques.
Conclusion
Nous avons vu comment créer notre premier modèle, un arbre de décision dans notre cas, et comment mesurer ses performances. Nous avons vu comment créer un pipeline simple avec une étape de préparation des données. Mais nous avons laissé beaucoup de choses de côté :
- Nous n’avons pas prétraité les données. Il y a peut-être des valeurs null ou aberrantes dans notre jeu de données qui biaisent notre résultat.
- Nous n’avons pas tenté de chercher de meilleurs paramètres pour notre arbre.
- Que se passe-t-il si on choisit un autre algorithme de classification ?
- Est ce que l’on peut pré-traiter nos données ?
- Comment s’assurer que le split que nous avons eu n’est pas biaisé ?
- Comment ensuite utiliser le modèle ?
Ce sont autant de questions qu’il reste à adresser et scikit-learn fournit des outils qui permettent de résoudre ces problèmes et que nous pourrons découvrir dans d’autres articles.